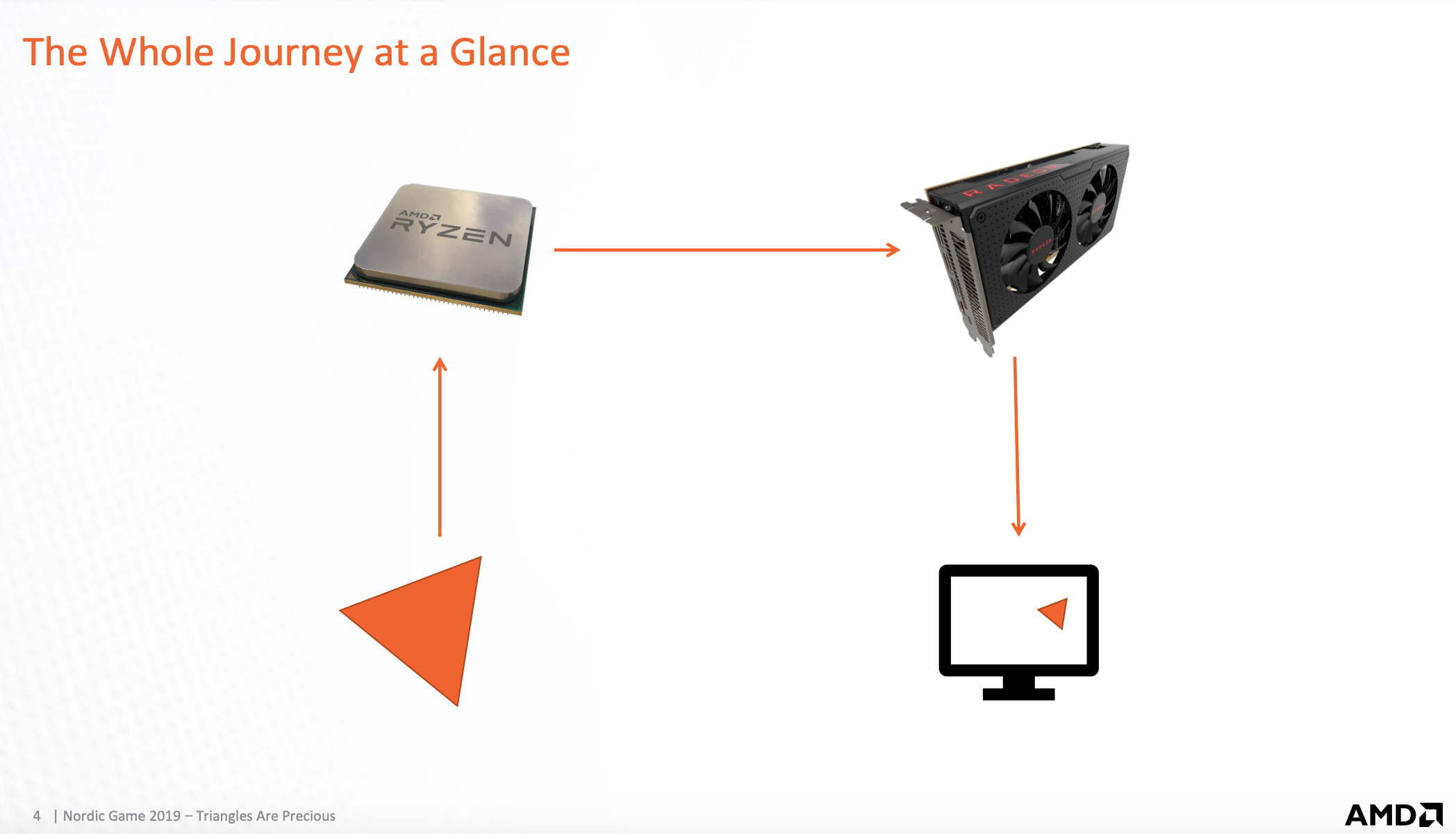
三角形渲染全貌
- cpu将三角形从硬盘加载到内存
- cpu将内存数据拷贝到gpu显存
- gpu按照渲染管线流程将三角渲染完放到目标framebuffer
- 显示器按照刷新频率从交换区读取三角形信息,显示到屏幕
三角形制作
- 使用3d制作工具创建3d模型
- 三角形每个顶点有自己的属性(位置,法线,uv)

导出和导入
- 使用3d软件将3d模型导出对应的模型文件 (fbx,3ds,dae,abc,ply,obj,x3d,stl)
- 再将3d模型导入游戏引擎,每个引擎有自己支持的格式,将对应的文件加载为引擎自己需要的数据,再加工(比如Unity调整对应的对象属性)后来供游戏引擎改造后最终在游戏应用上渲染使用
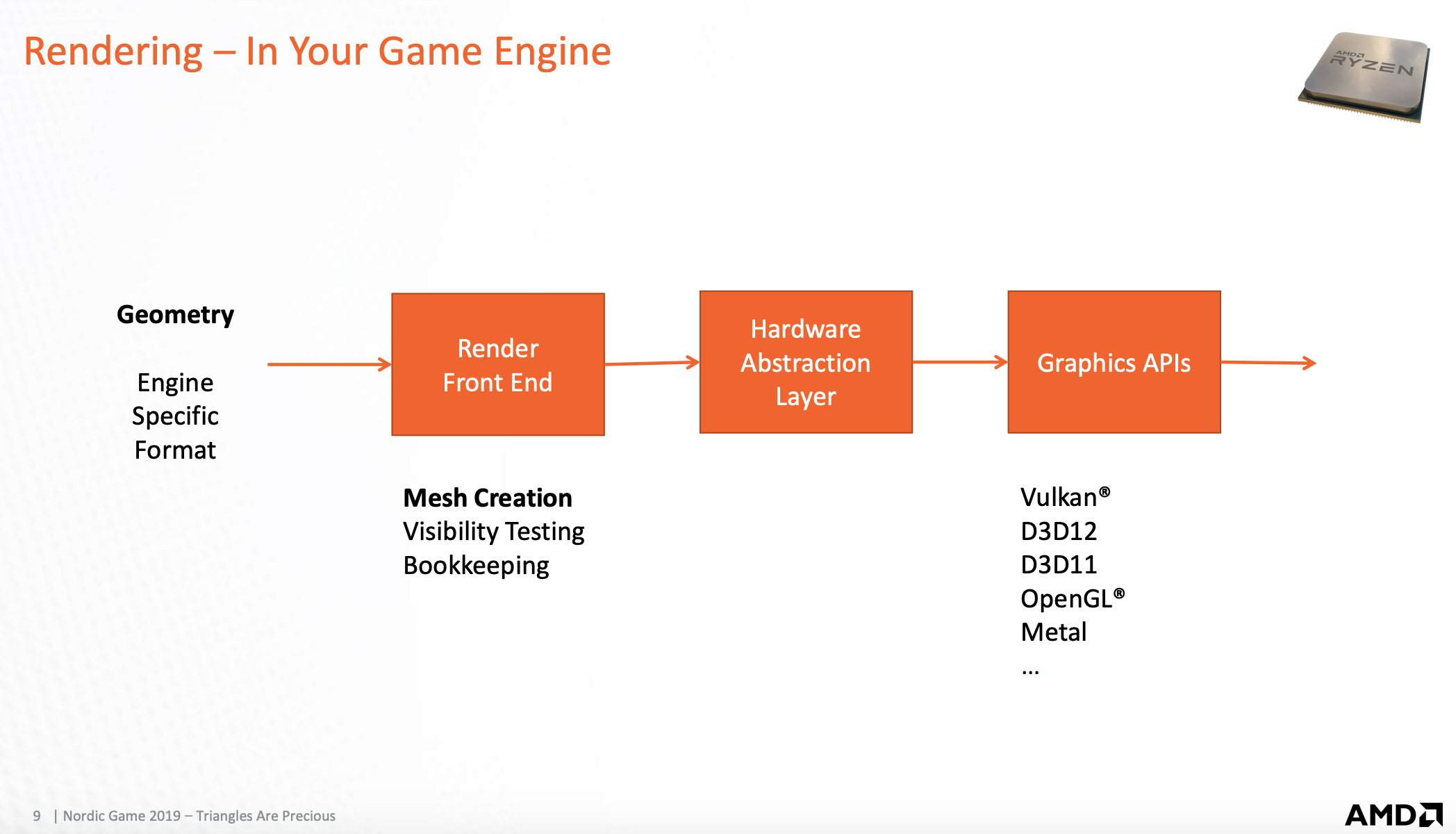
渲染
游戏引擎
游戏引擎需要处理的事情
- 将数据加载然后创建需要的对象
- 在CPU端通过相应的规则将不需要的数据舍弃
- 配置GPU端的状态属性,比如shader,渲染流程,模板,深度测试,融合方式,以及GPU端需要的数据从CPU端拷贝到GPU端显存,设置对应的渲染目标buffer
- 将绘制命令发送到GPU,继续第三步
创建网格,CPU端
由于CPU需要从硬盘加载数据到内存,然后再将对应数据发送到GPU端供使用。因为GPU也是连接在CPU的BUS总线,所以需要CPU端发送数据到GPU。
- 所有的API同样的流程
- 为顶点创建缓存
- 为索引创建缓存

创建网格,GPU端
将CPU端的mesh通过硬件抽象层发送到GPU端,本质上是将CPU缓存发送到GPU显存

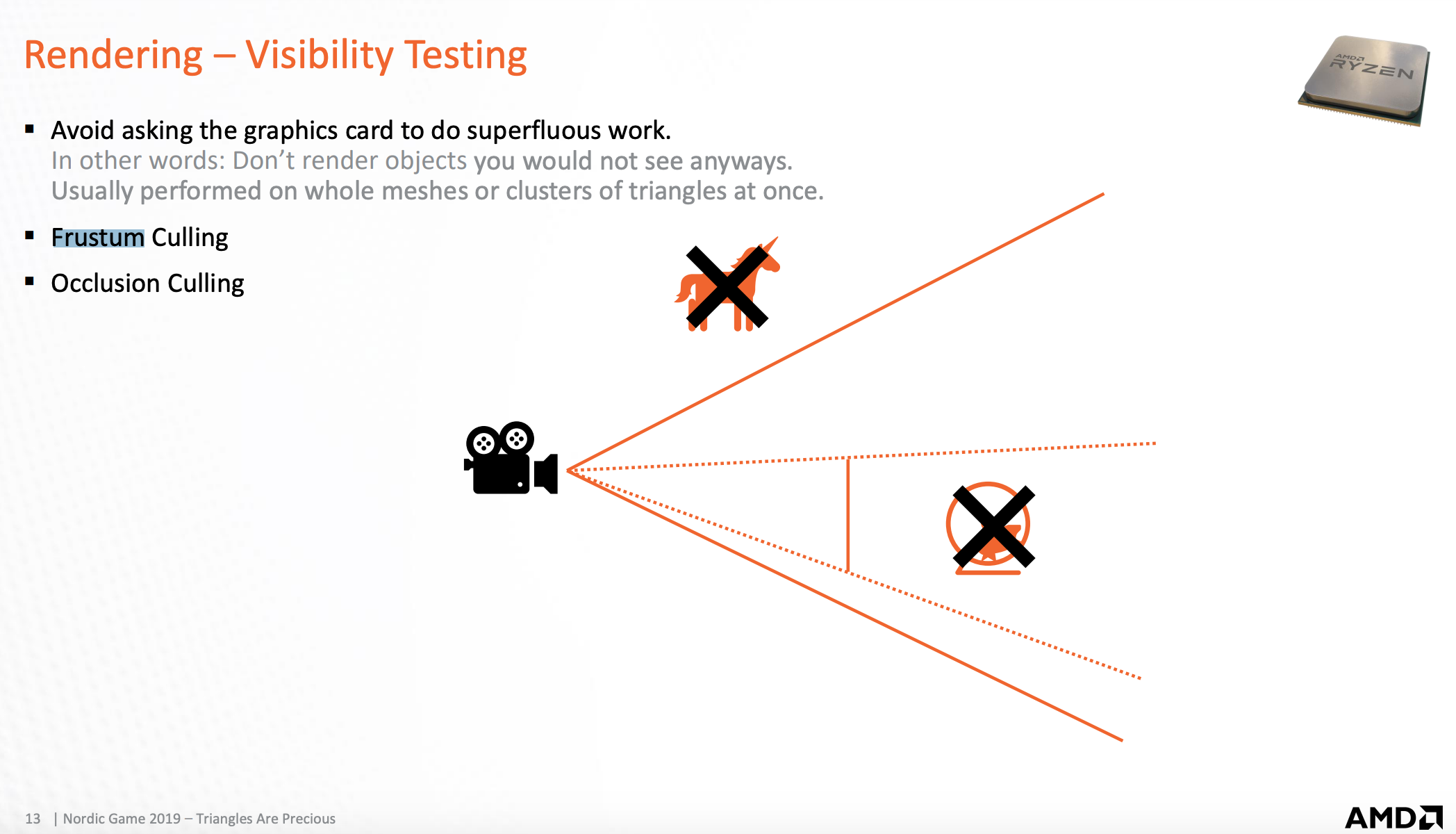
可见性测试
避免显卡多余的工作,使用可见性测试,将看不见的物件剔除掉,使用以下两种方式:
- 视椎体剔除 (Frustu culling)
- 遮挡剔除 (Occlusion culling)
图形驱动全貌
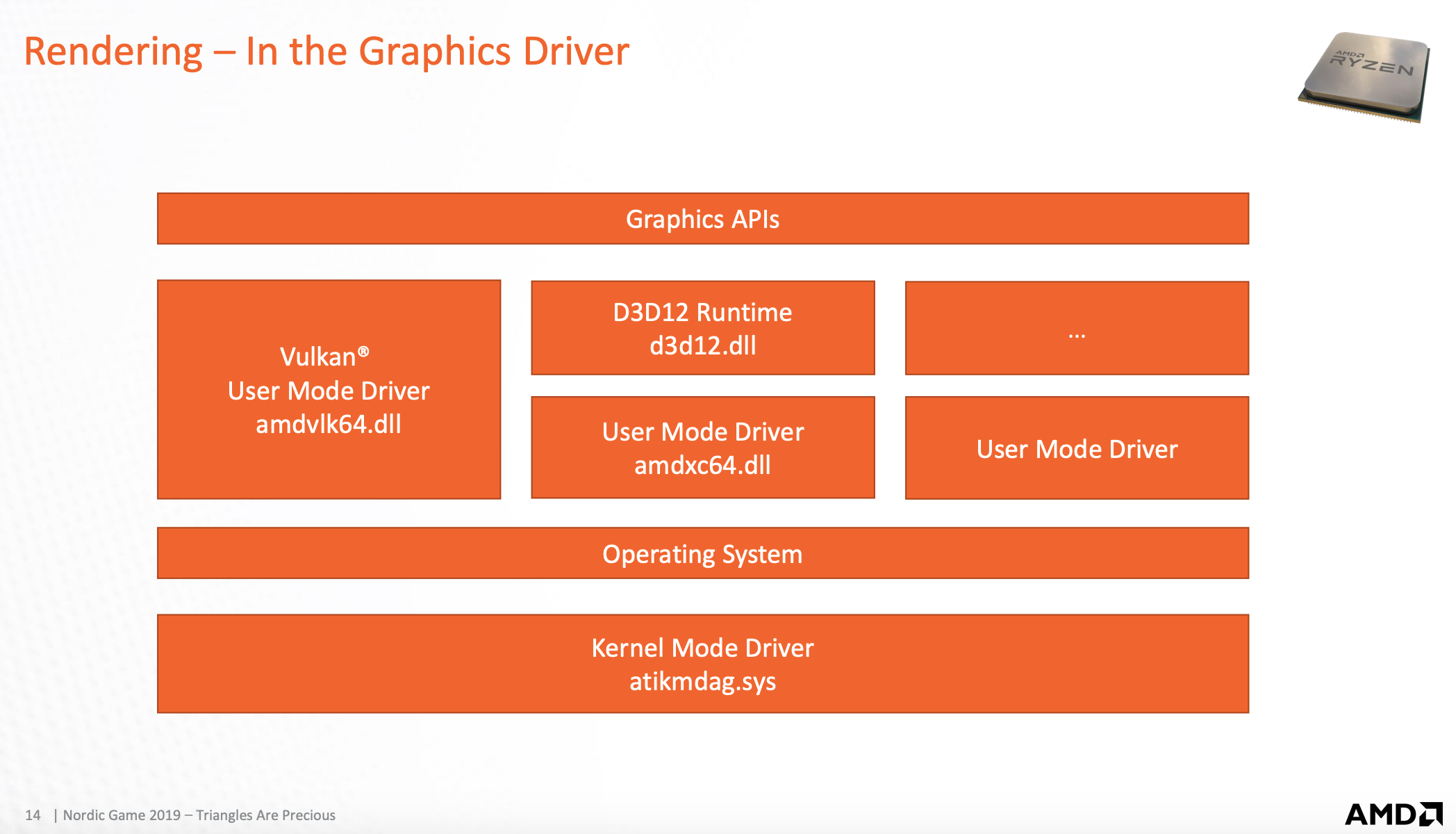
图形接口
供开发者使用,抽象层次更高,开发者只需按照对应的规则来设置GPU端渲染状态以及属性,同时组装命令,将命令发送出去。
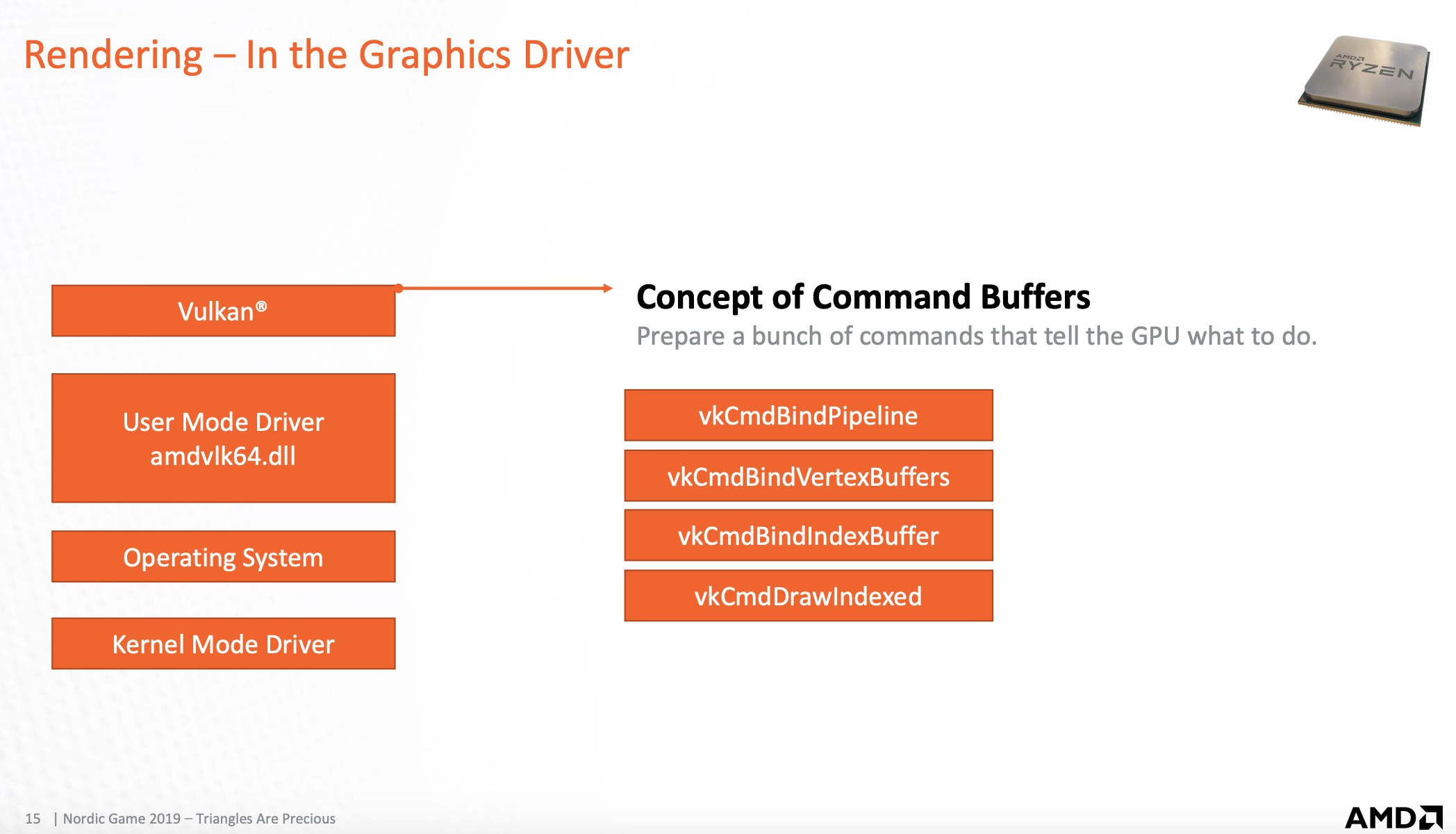
用户模式驱动
驱动这层级,将上层API包装好的结构数据解析转换成GPU端使用的数据。
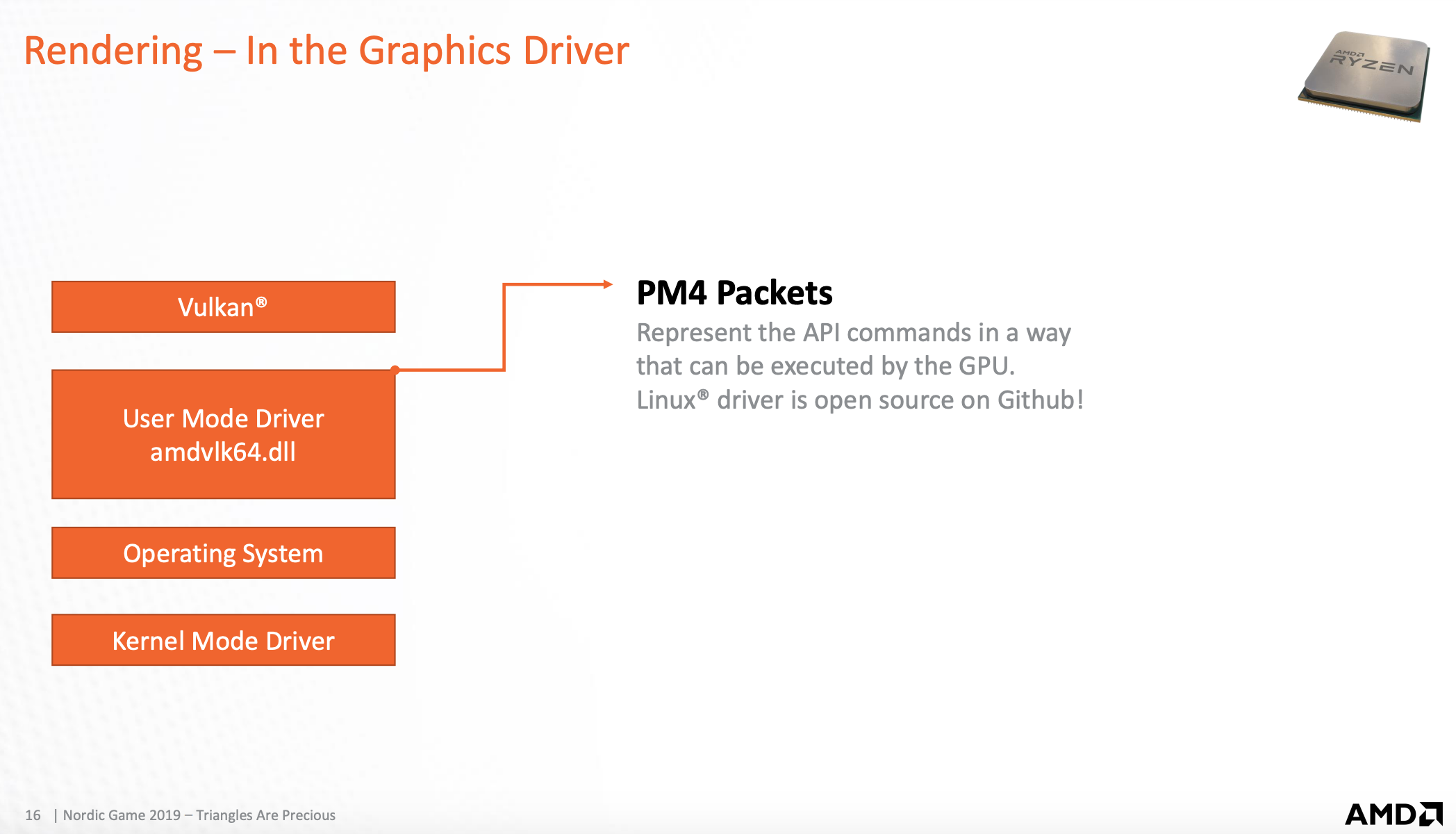
用户模式-CPU端PM4结构
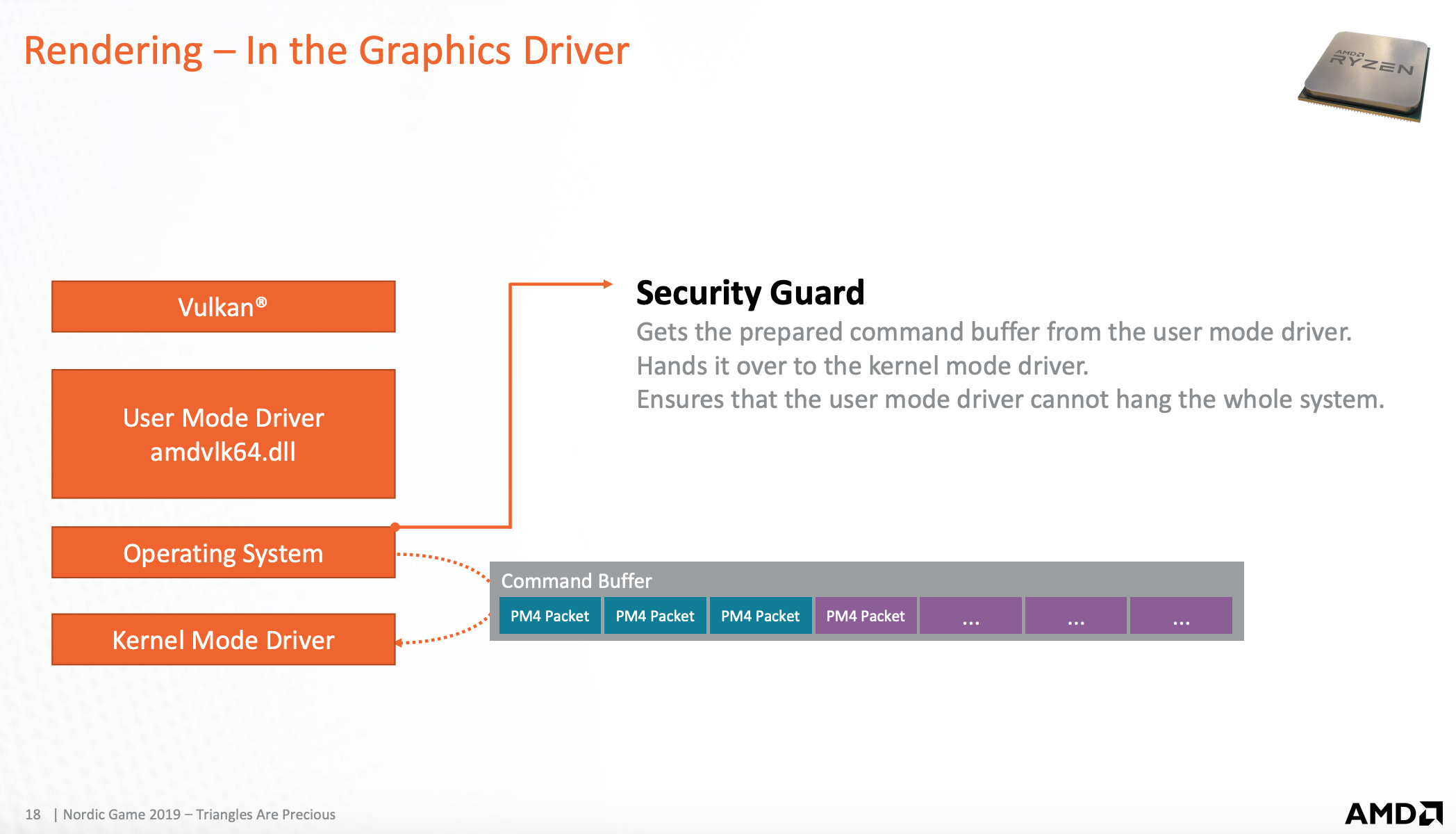
操作系统层的作用
操作系统这个层级来检查命令的安全性。
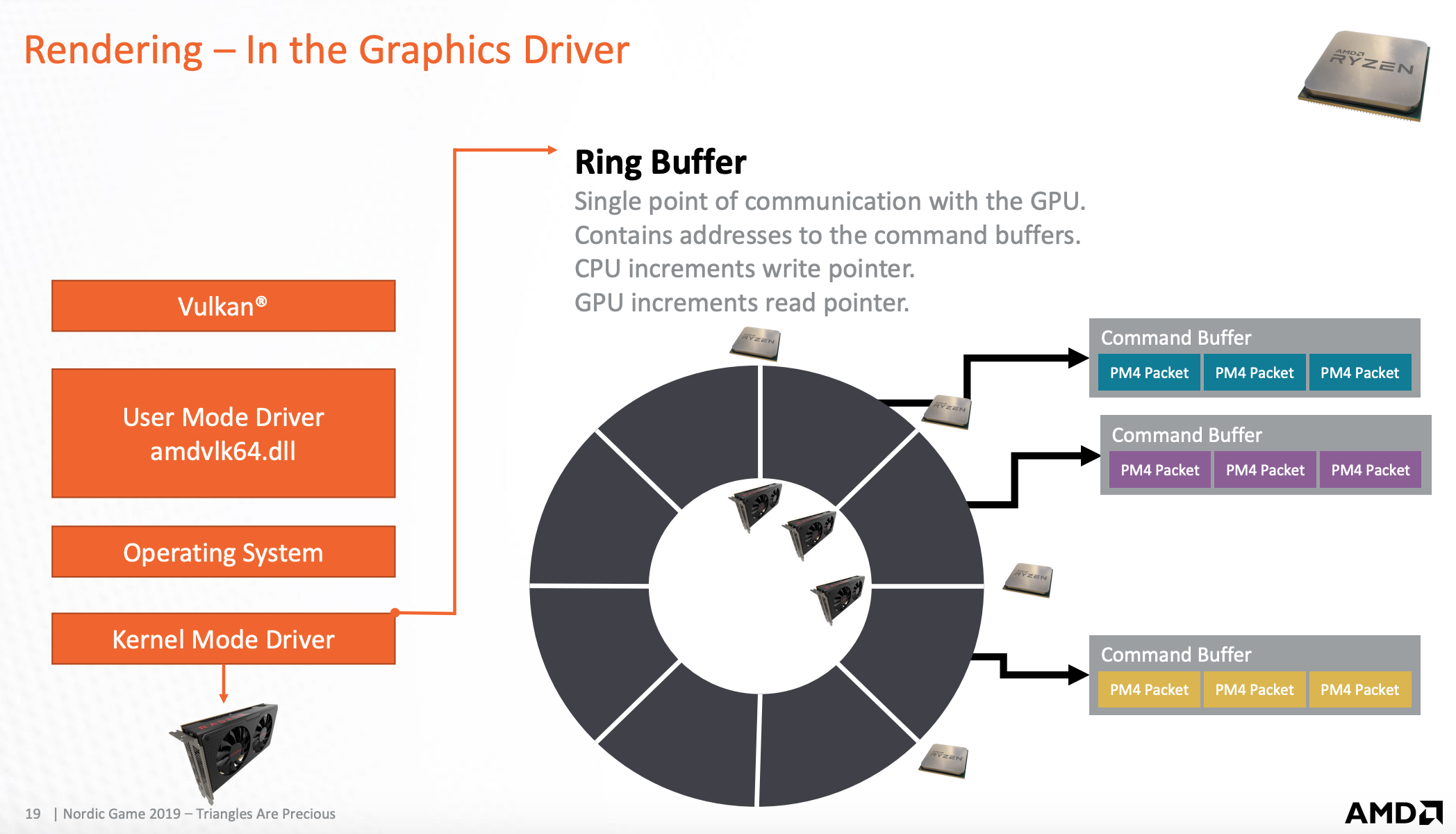
CPU 和 GPU 连接桥
环状缓存,CPU指向写指针,GPU指向读指针
GPU 端介绍
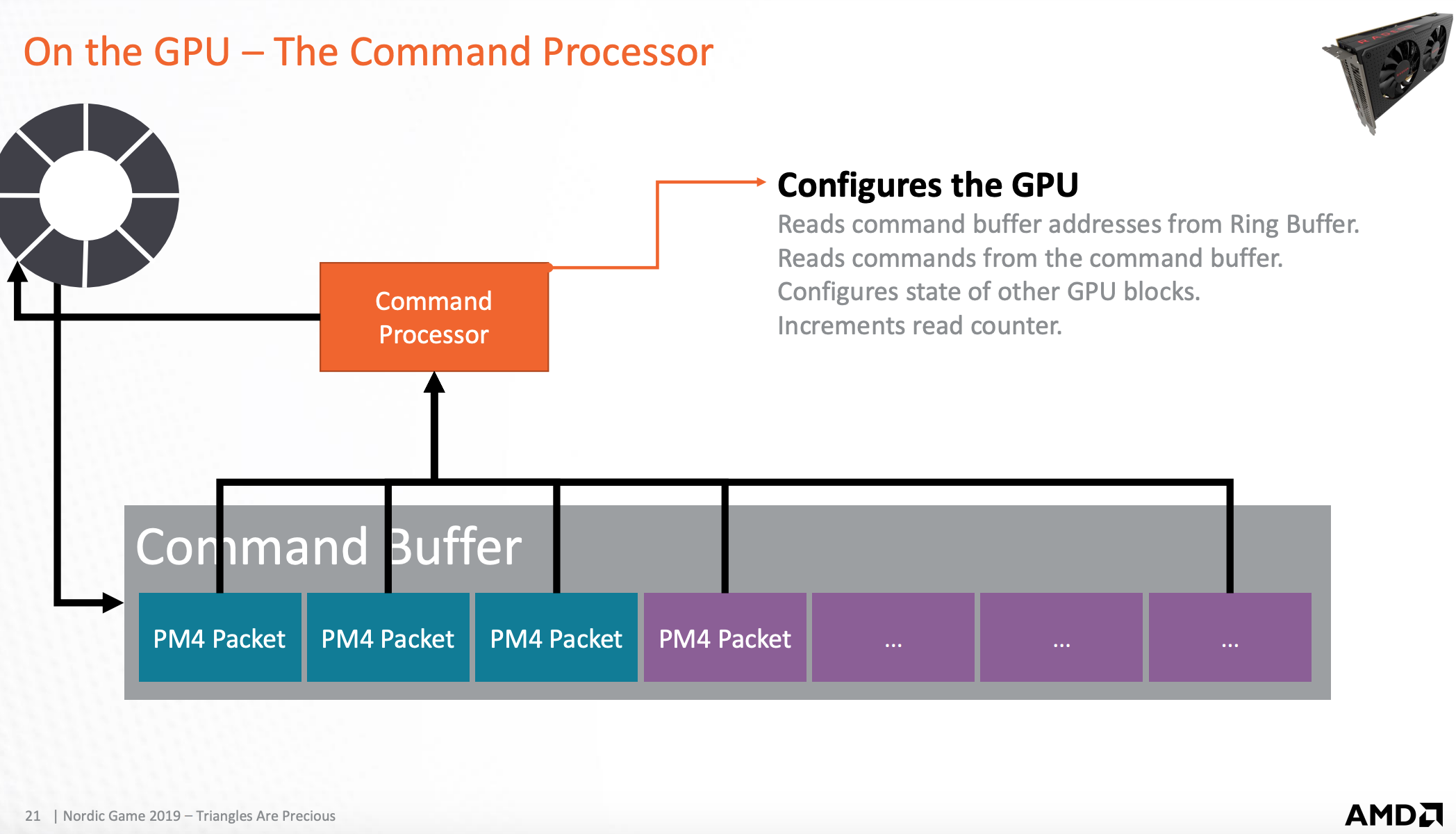
命令处理器
从环状缓存读取 Command Buffer,然后从 Command Buffer 解析出 Command,最后增加读缓存指针。
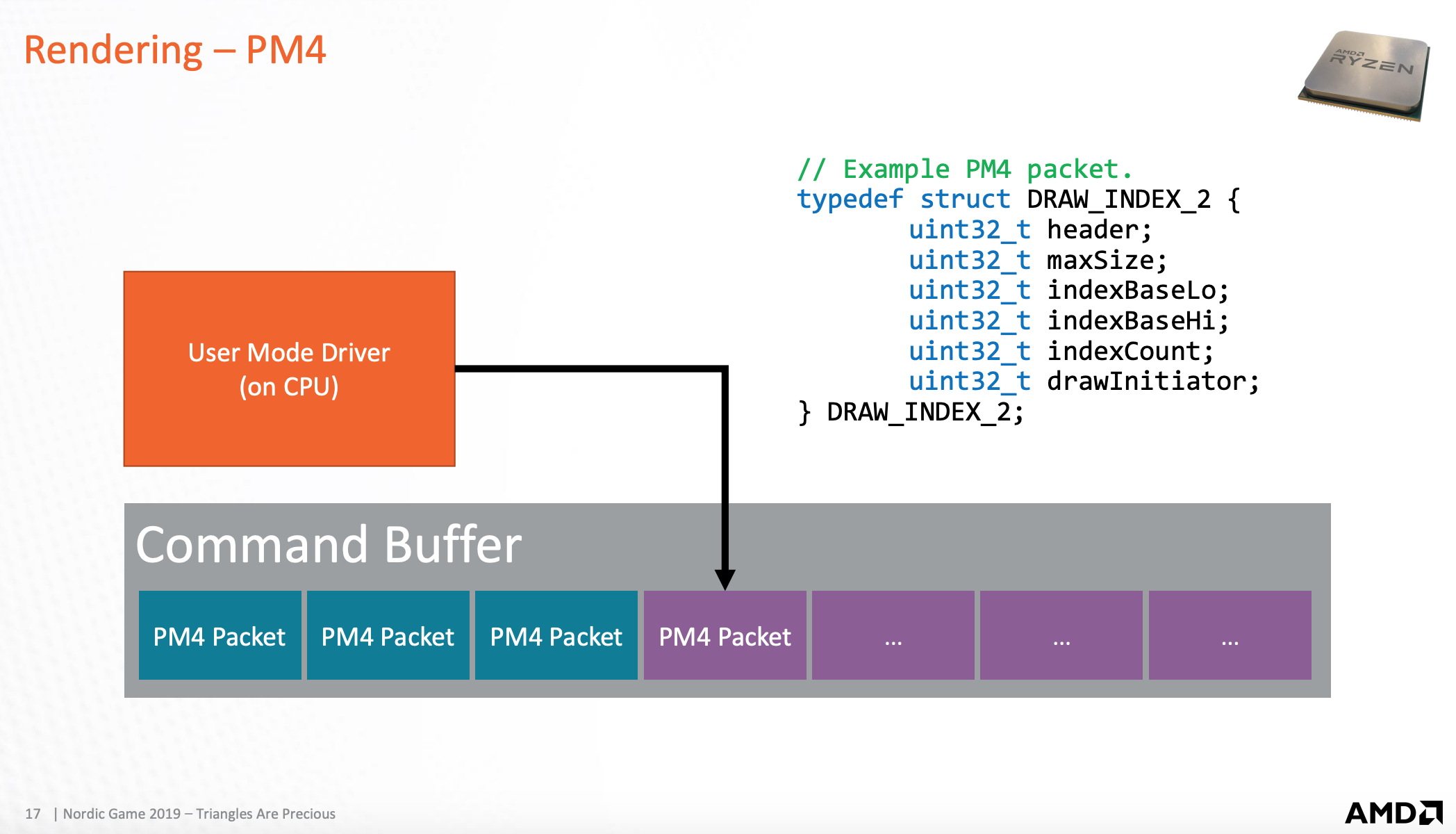
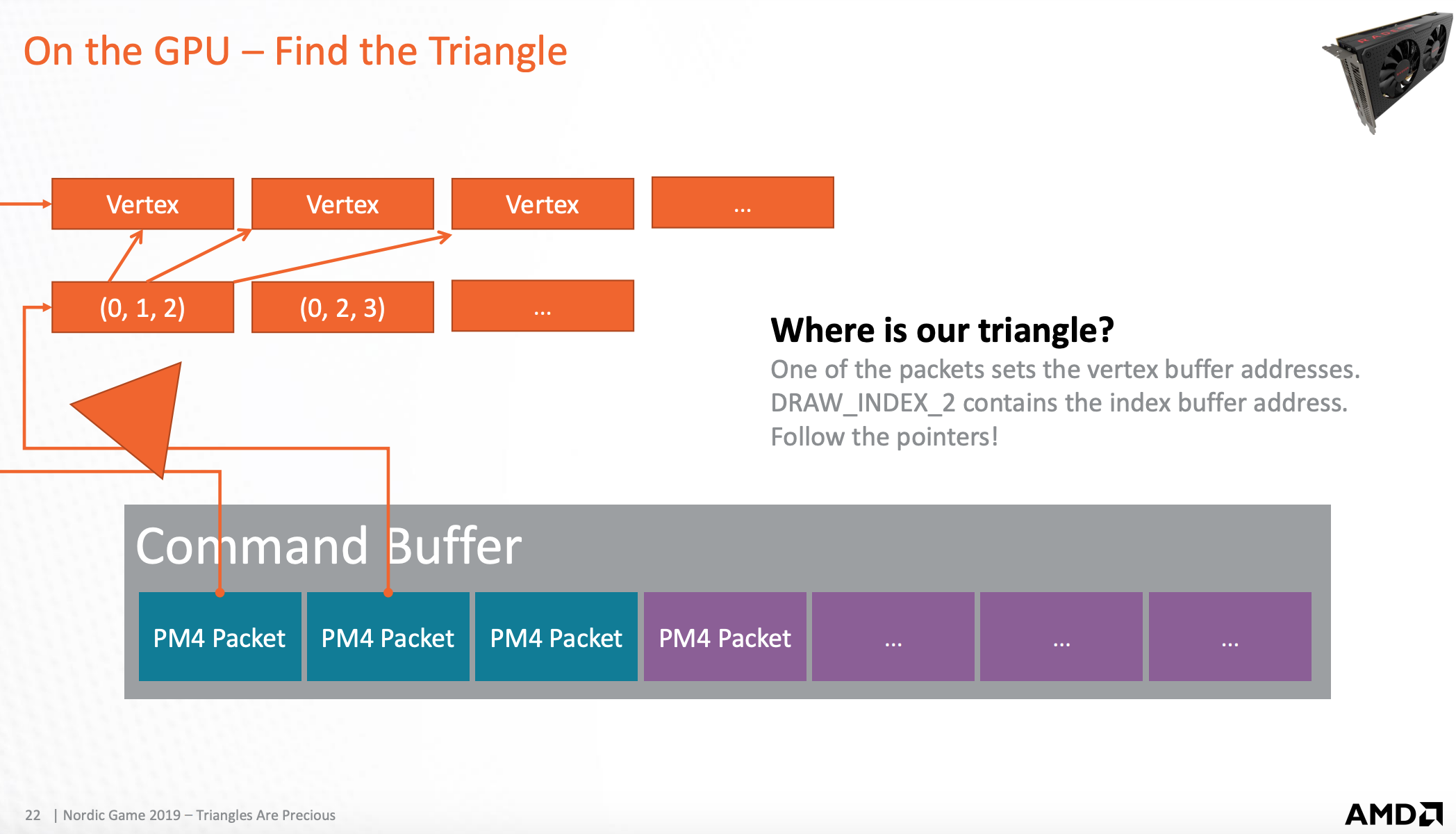
从 packet 解析出三角形信息
Command Buffer 由 packet 组成,packet 里有三角形缓存地址信息。
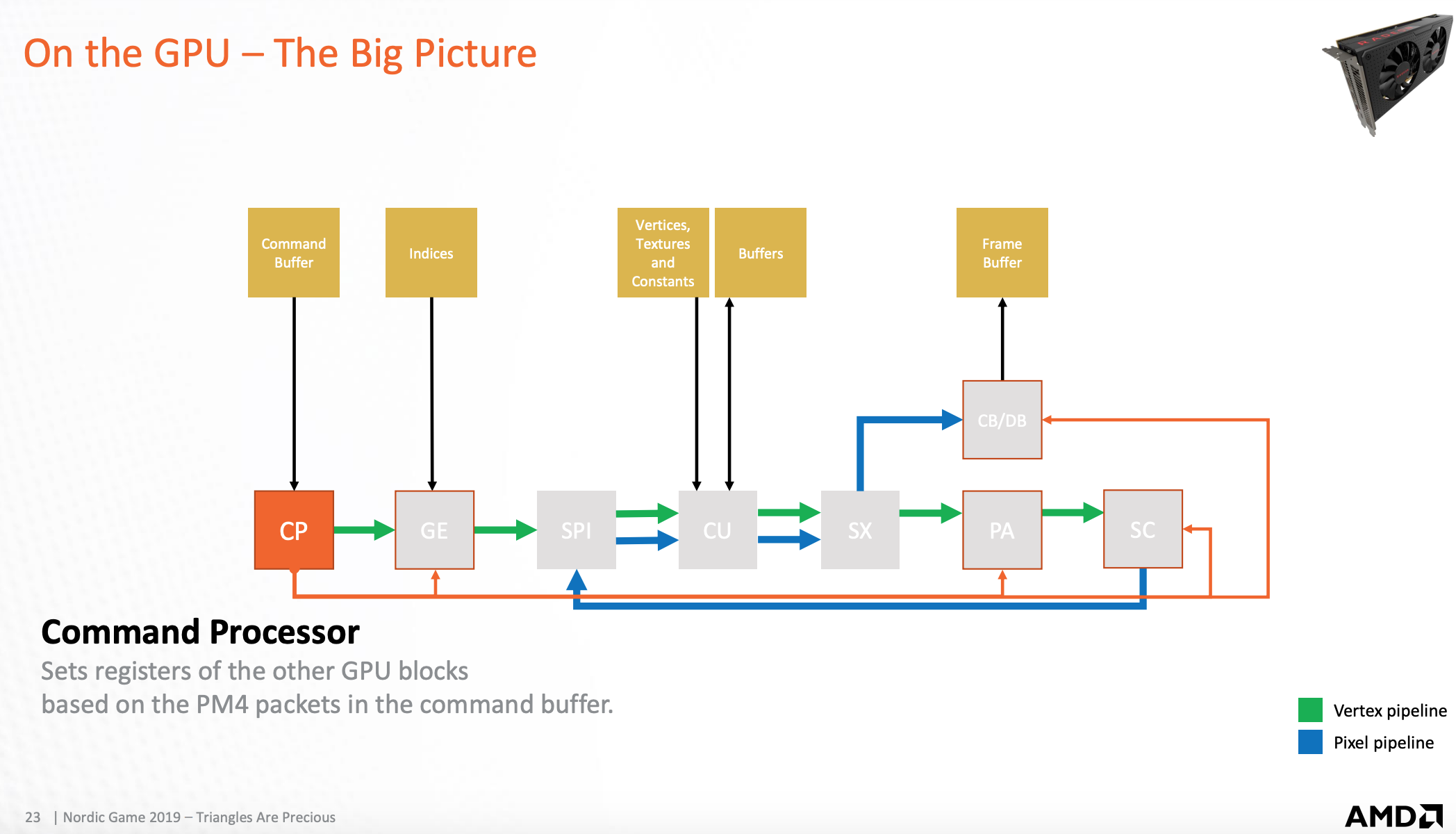
GPU-命令处理器
设置寄存器值,解析packet 命令。
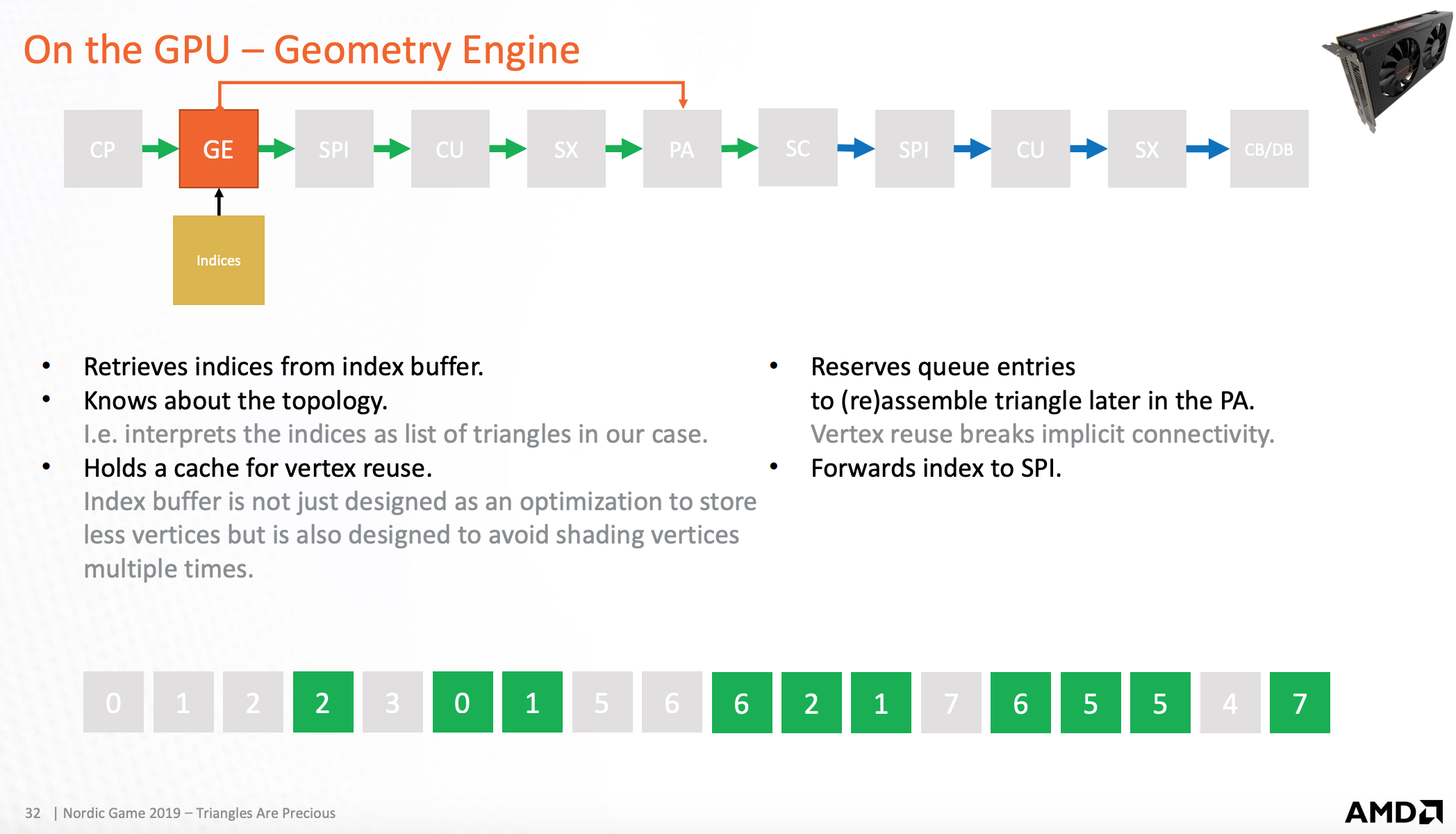
GPU-几何处理器
处理图片构成,然后将信息发送到着色处理器。
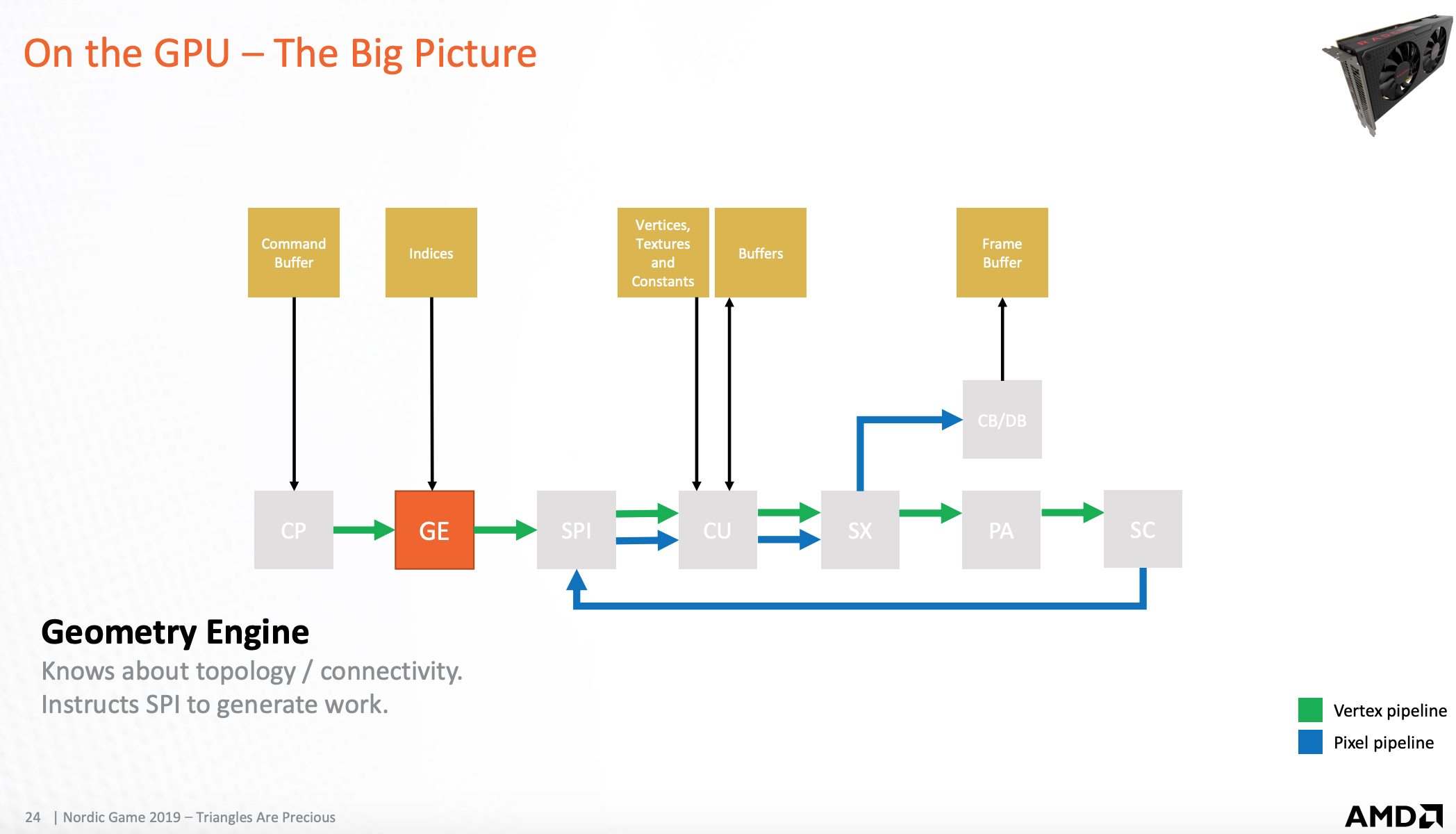
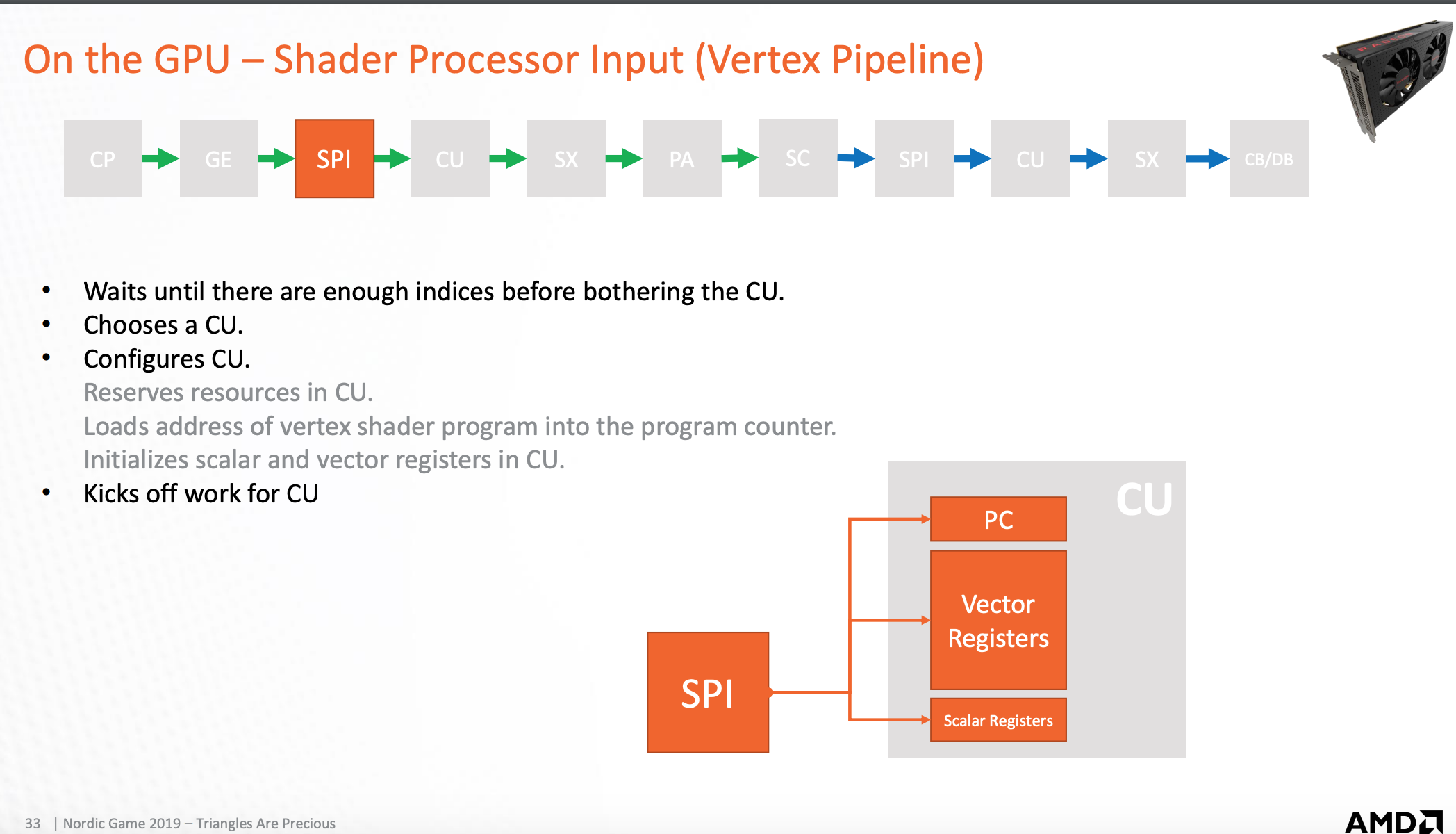
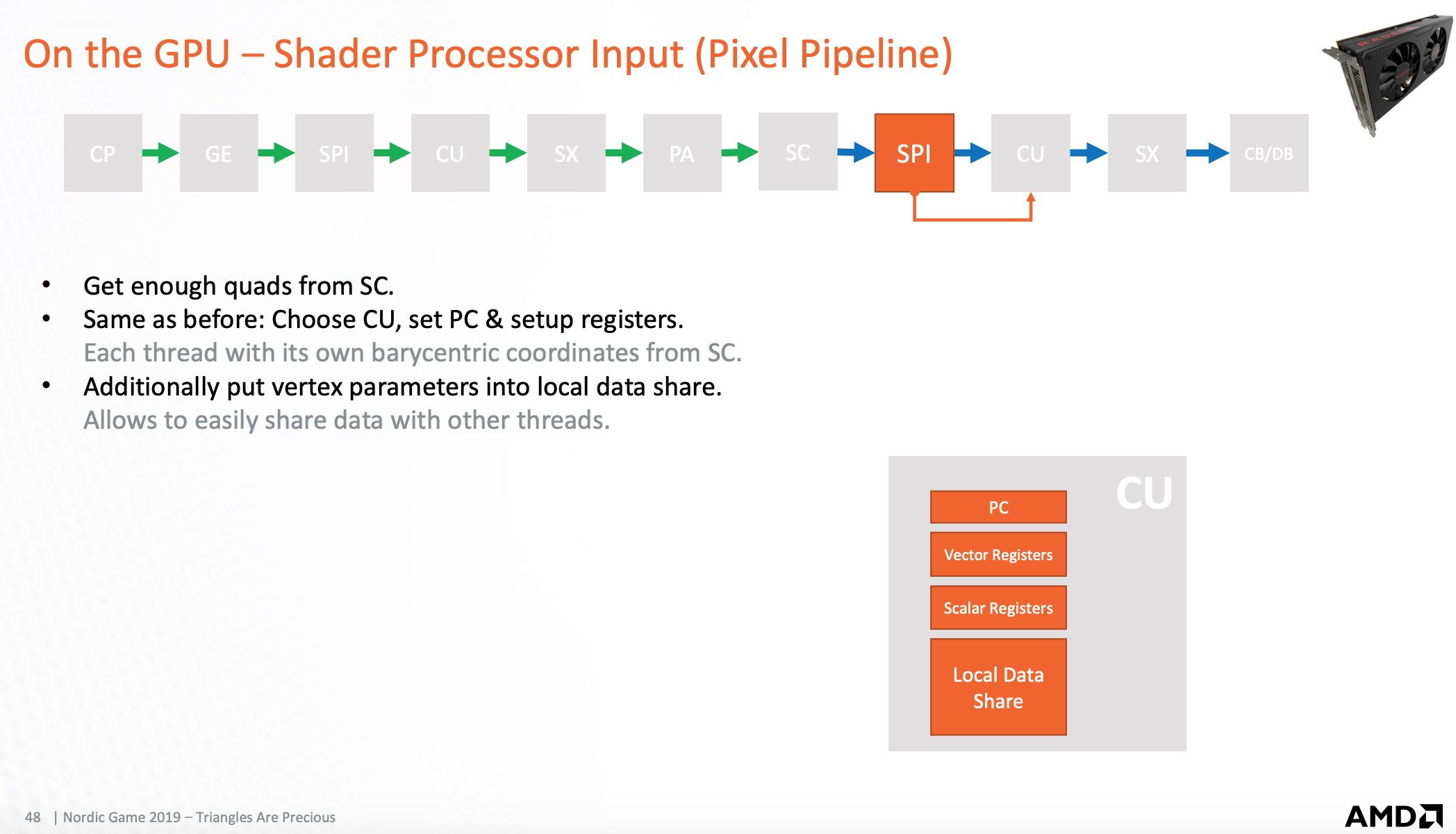
GPU-着色输入处理器
组装任务,发送到运算单元
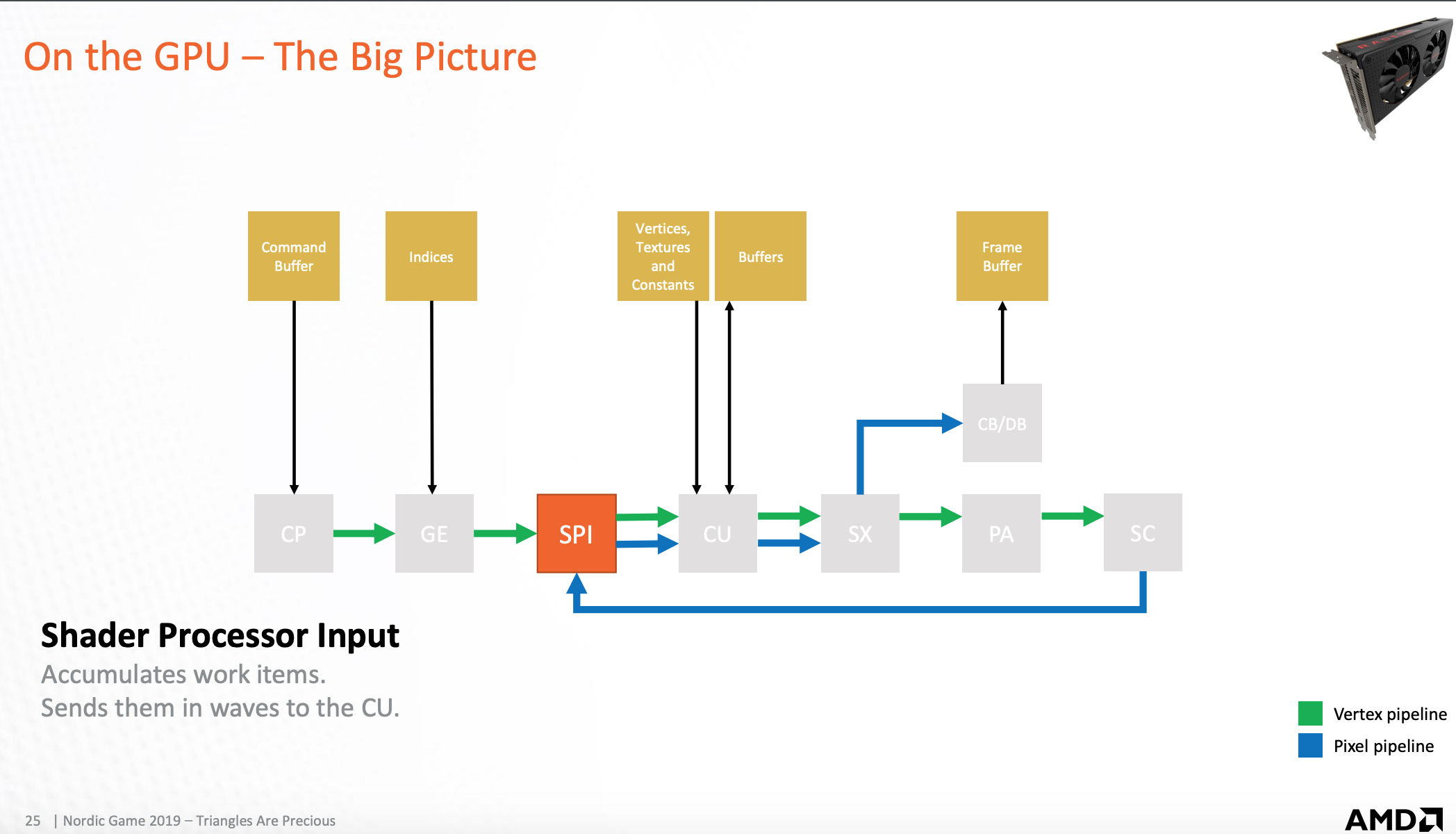
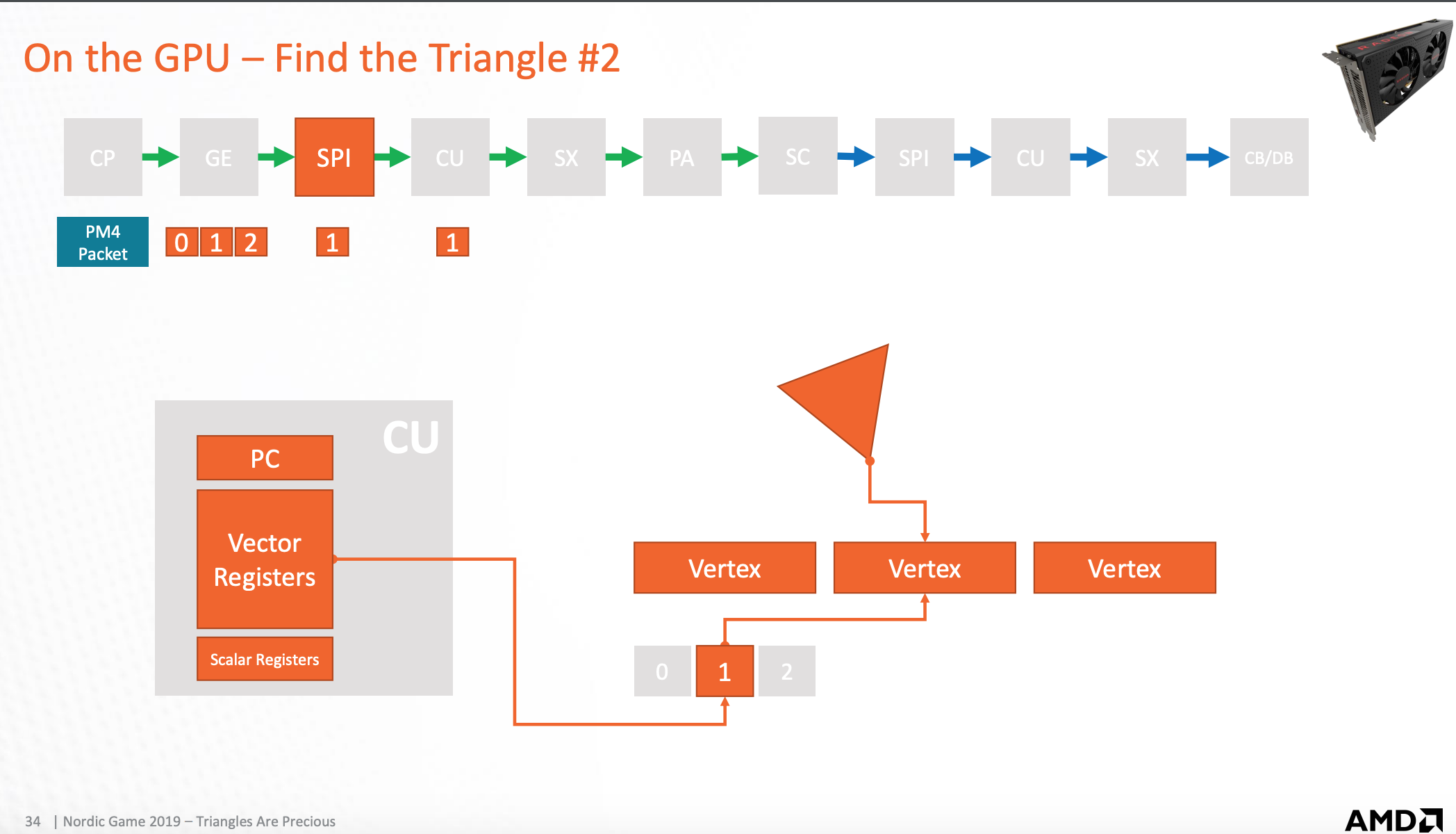
GPU-运算单元
运算单元可以读/写缓存,执行shader程序
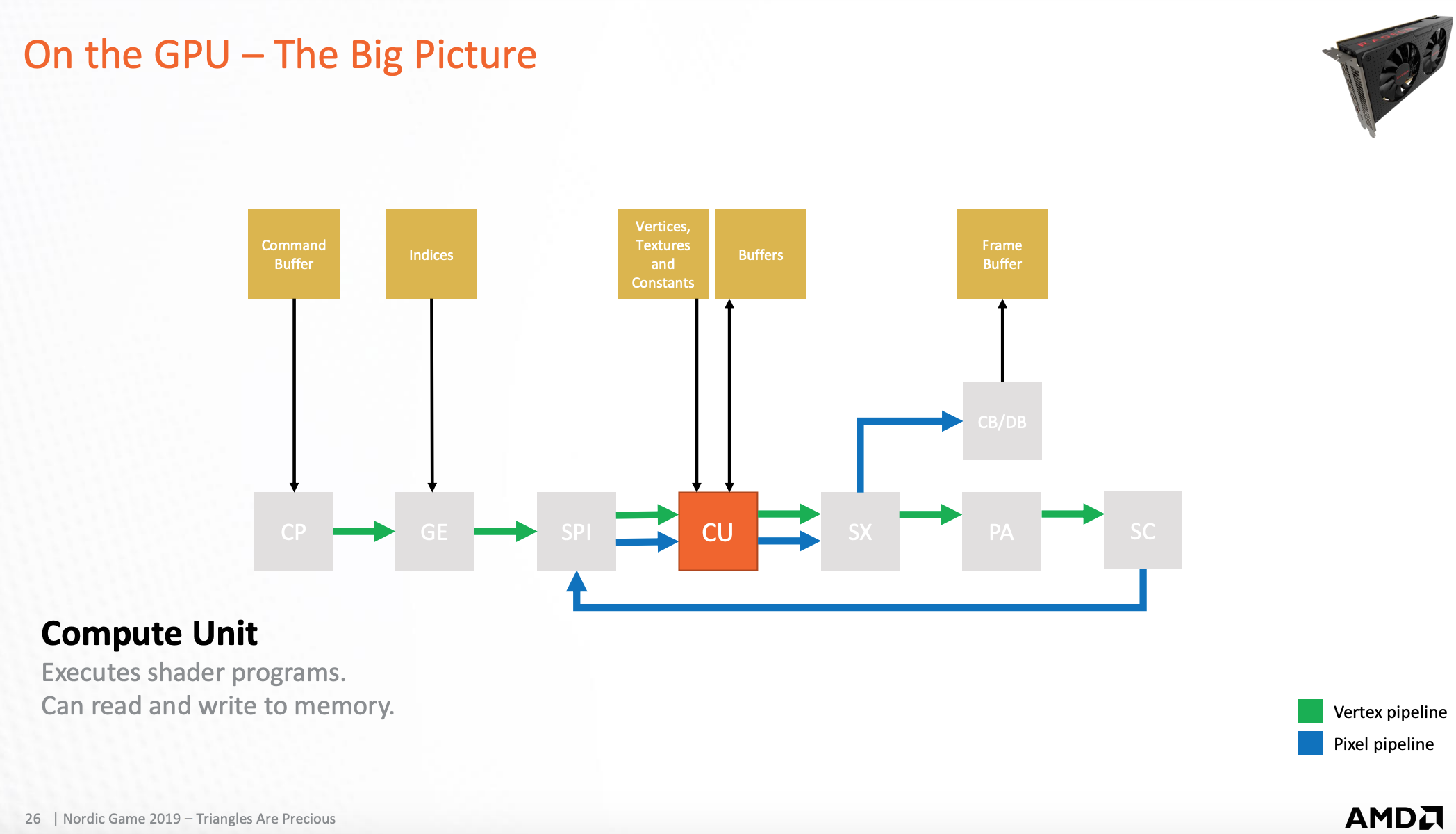
GPU-着色导出处理器
处理运算单元的输出任务
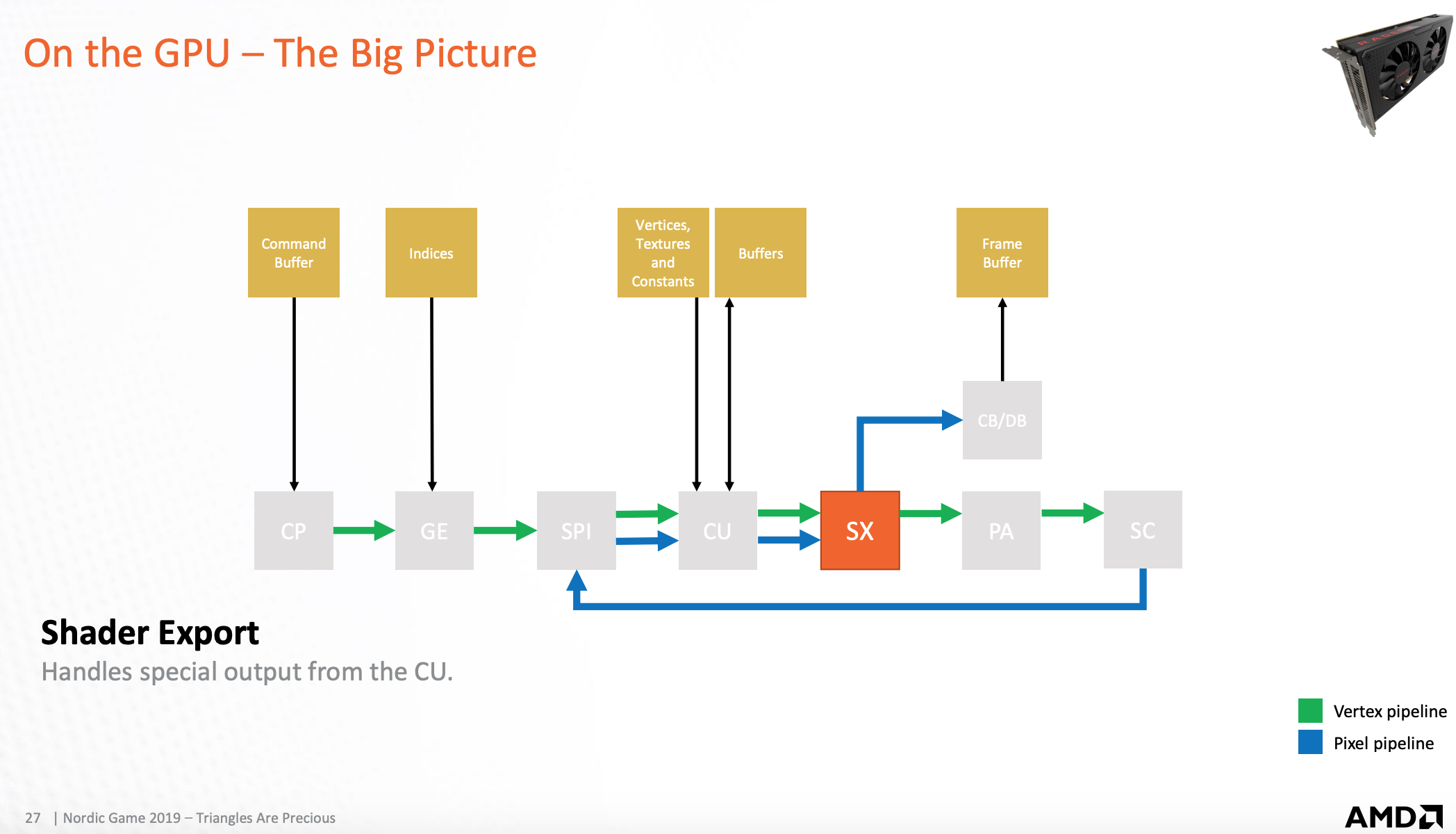
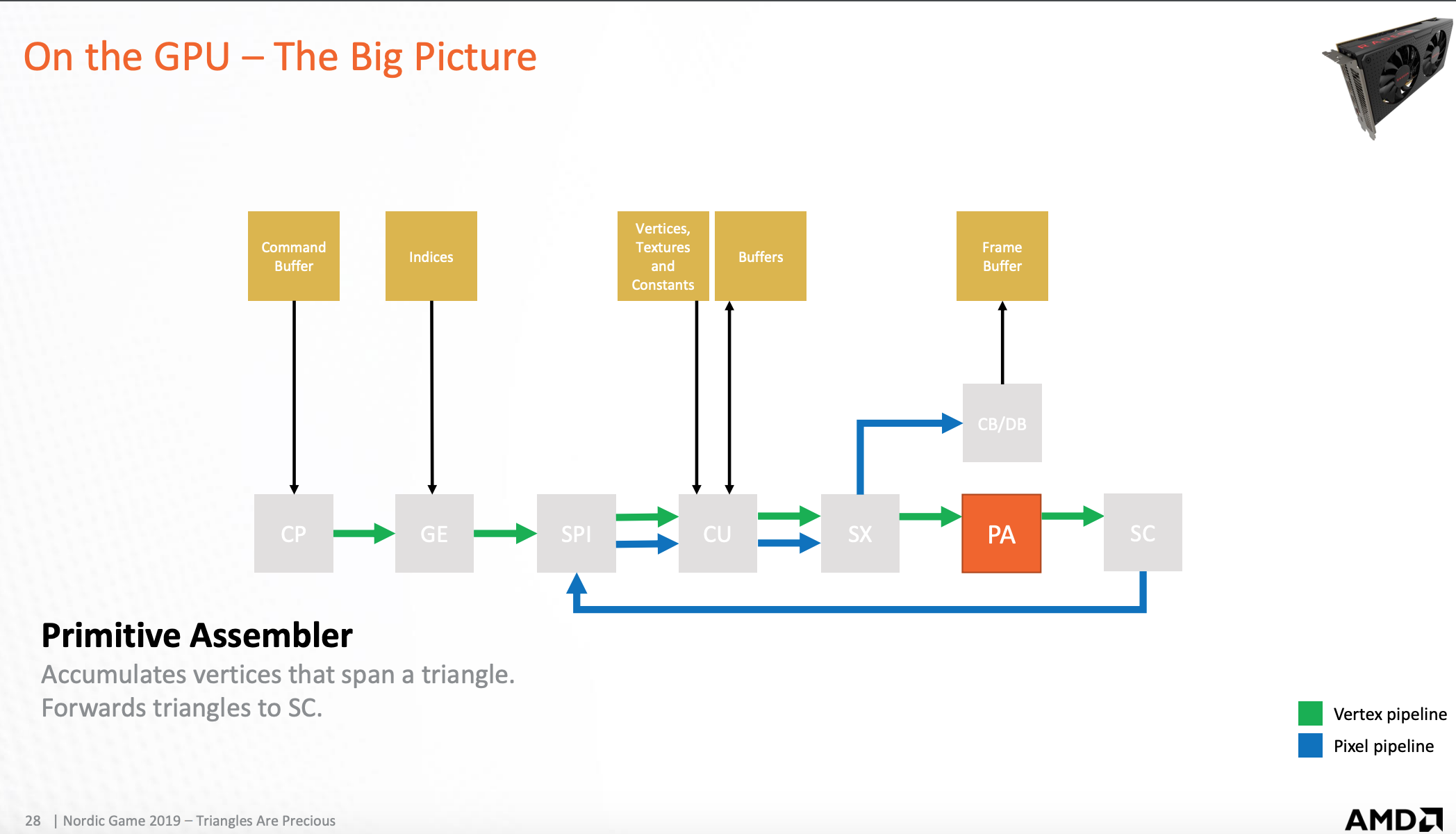
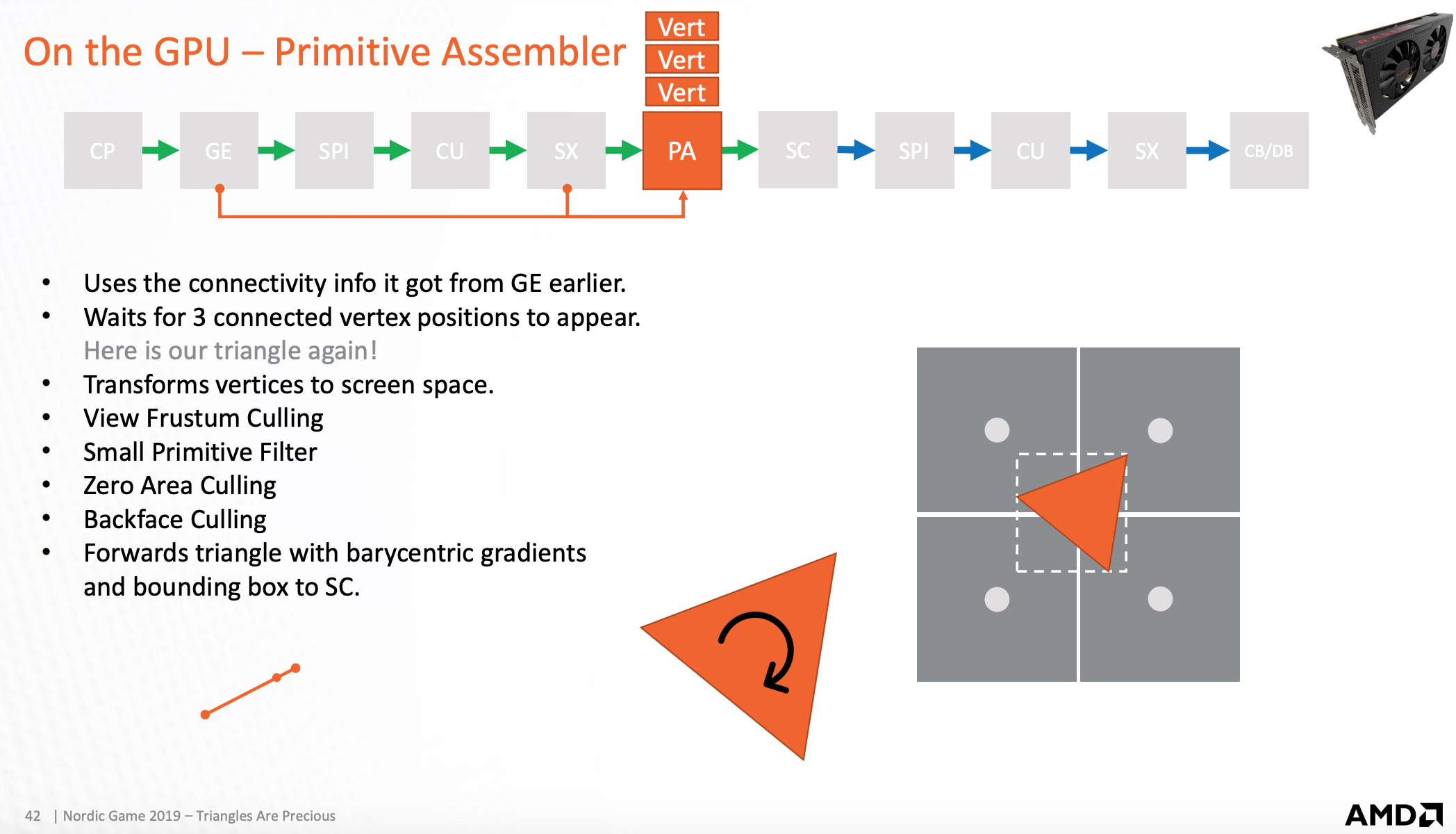
GPU-基础图员汇编器
将组成三角形的顶点发送到光栅化扫描器
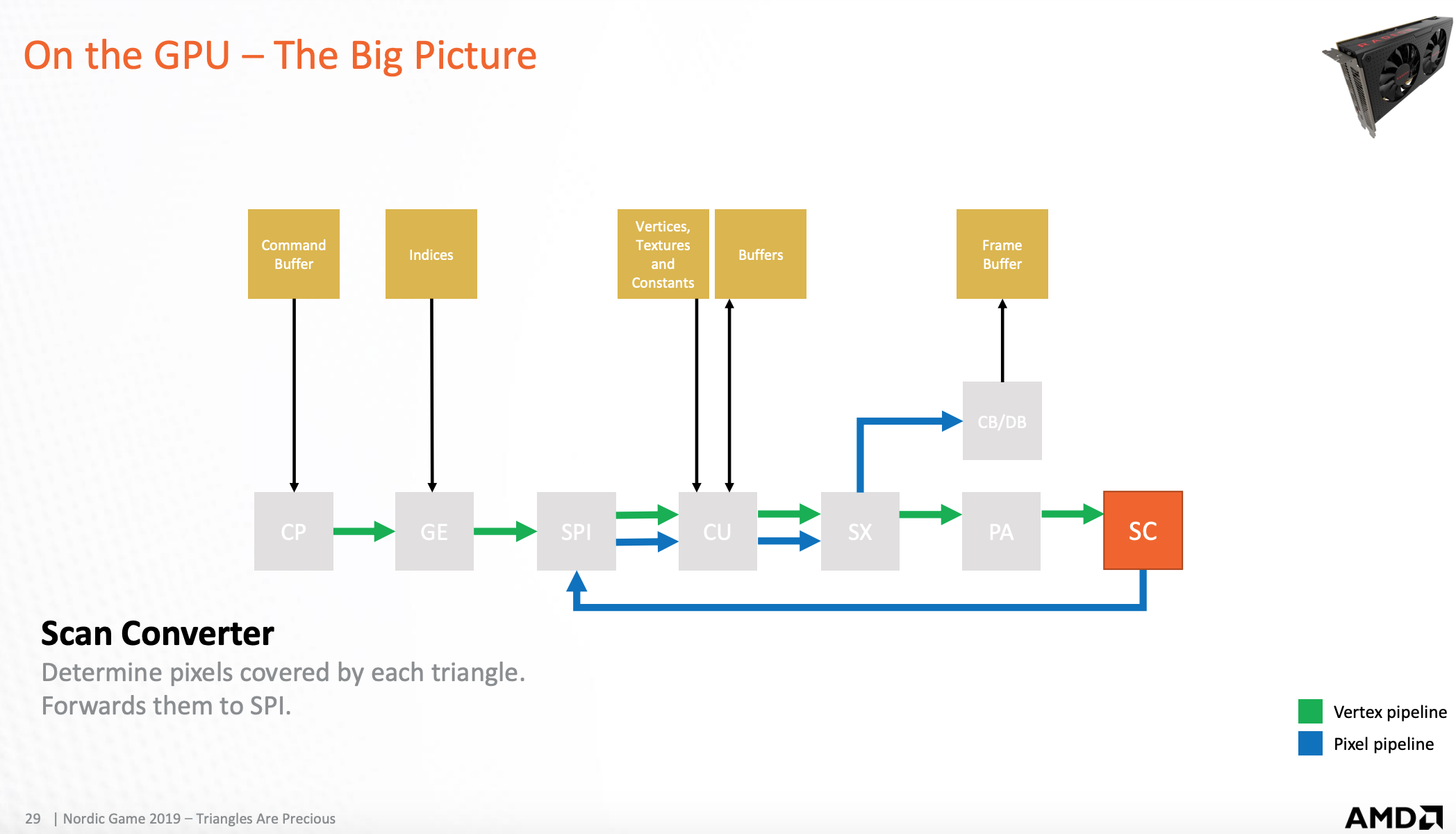
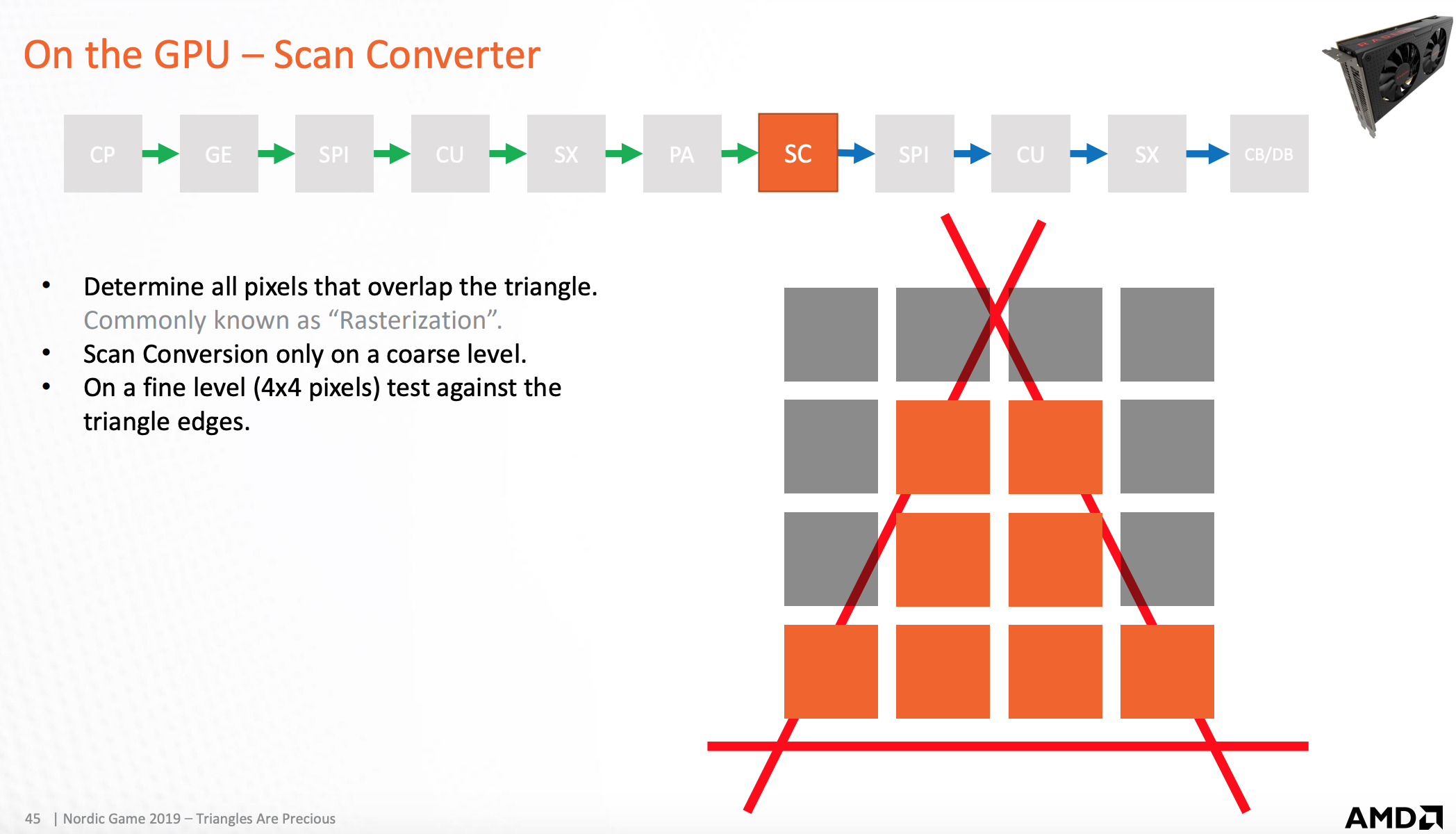
光栅化扫描器
检测被三角形覆盖的像素,然后将像素点发送到着色处理器
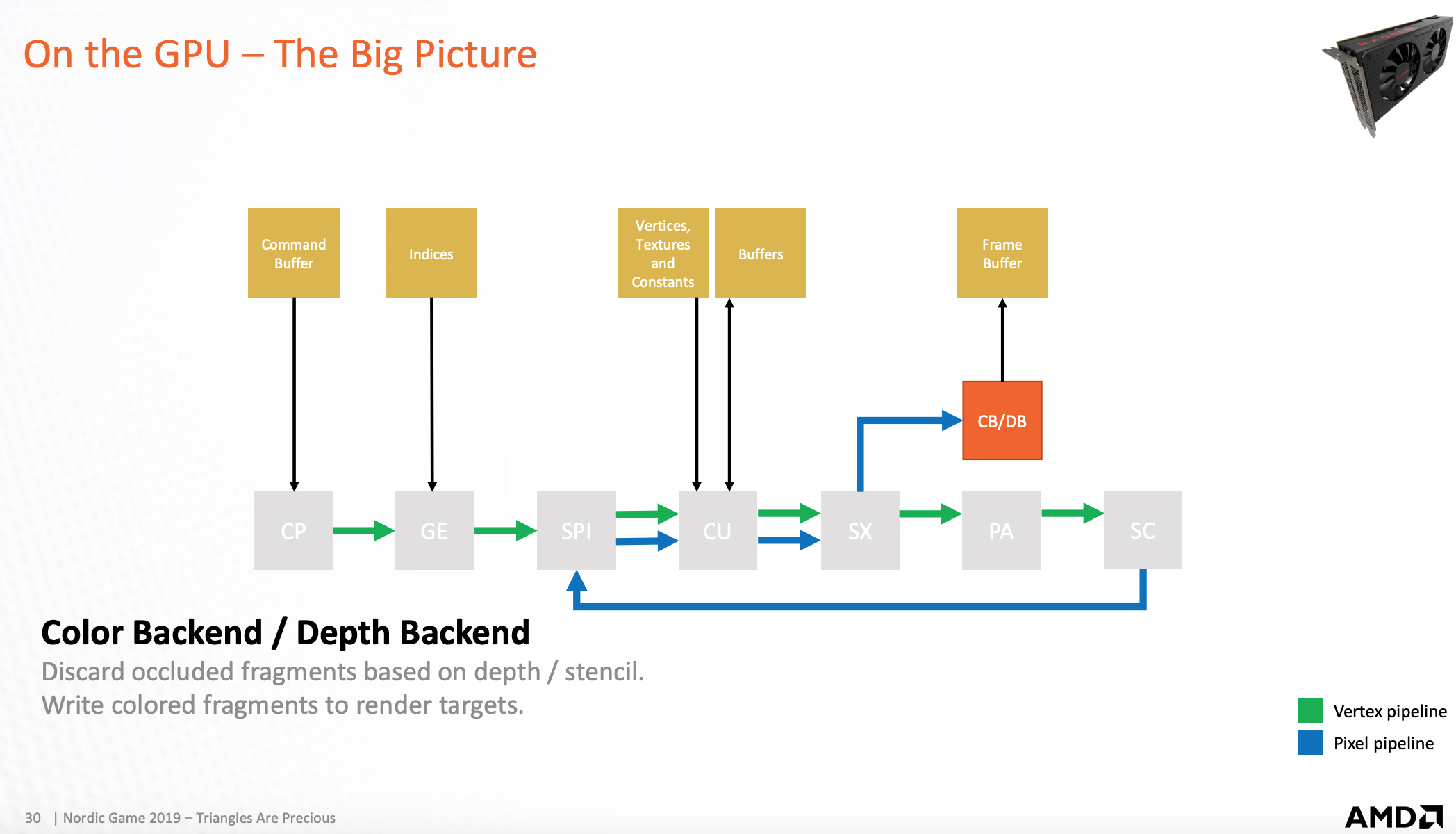
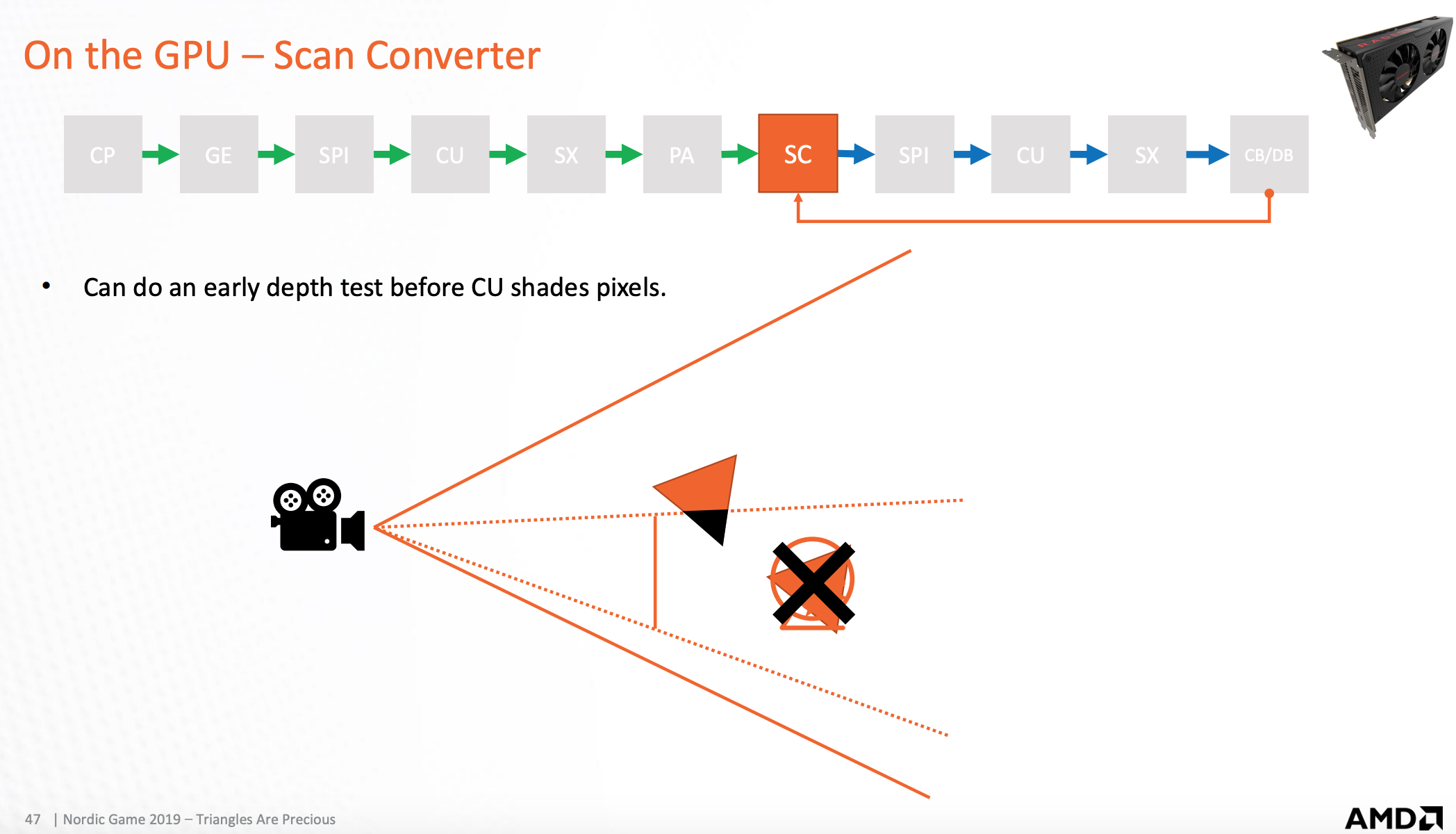
颜色和深度处理器
根据深度/模板将被剔除的像素舍弃,然后将着色后的片元写入渲染目标缓存
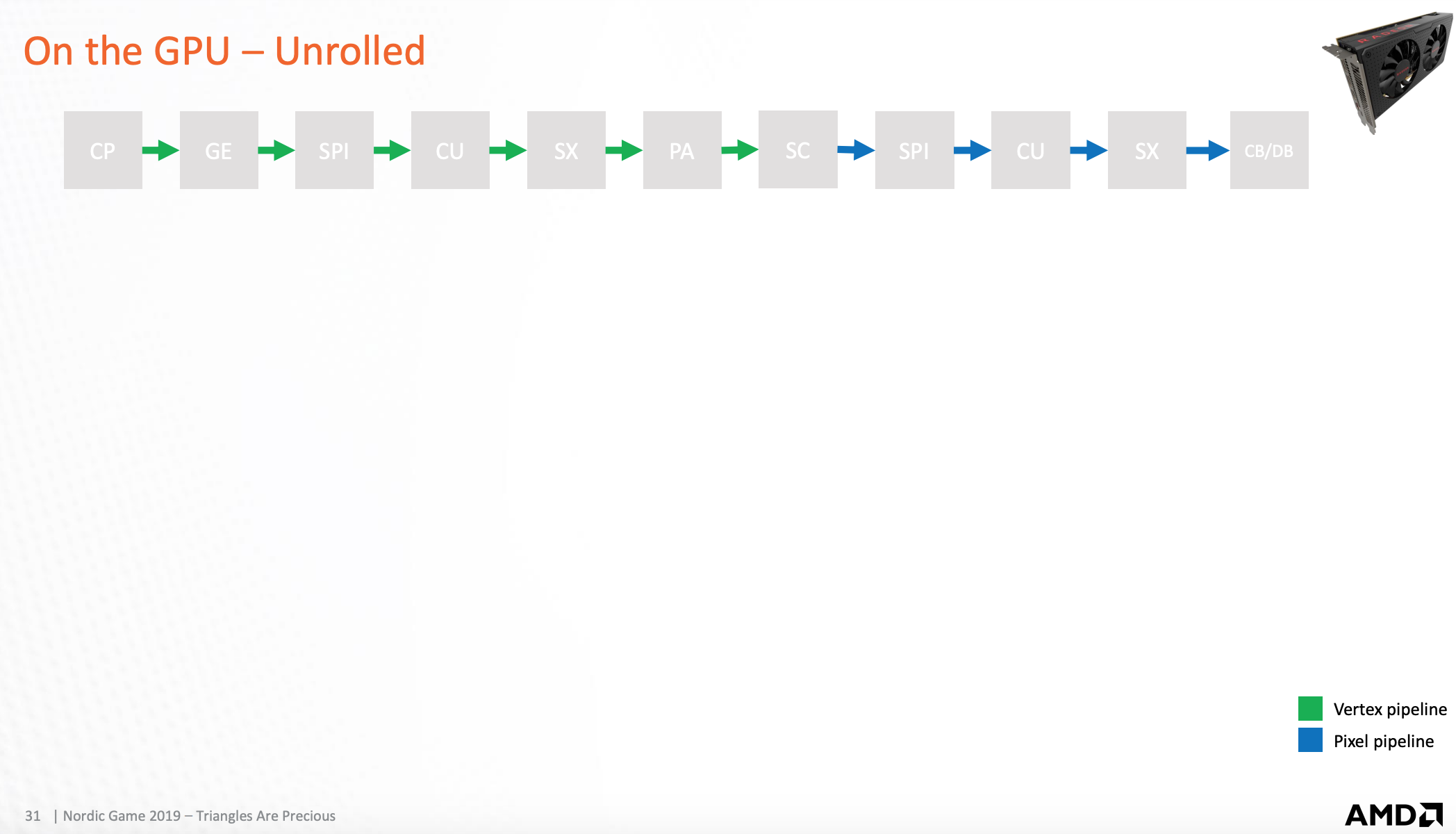
GPU处理完整流程
整个完整渲染流程
几何处理器详细
shader输入处理器(顶点管线)
运算单元 (顶点管线)
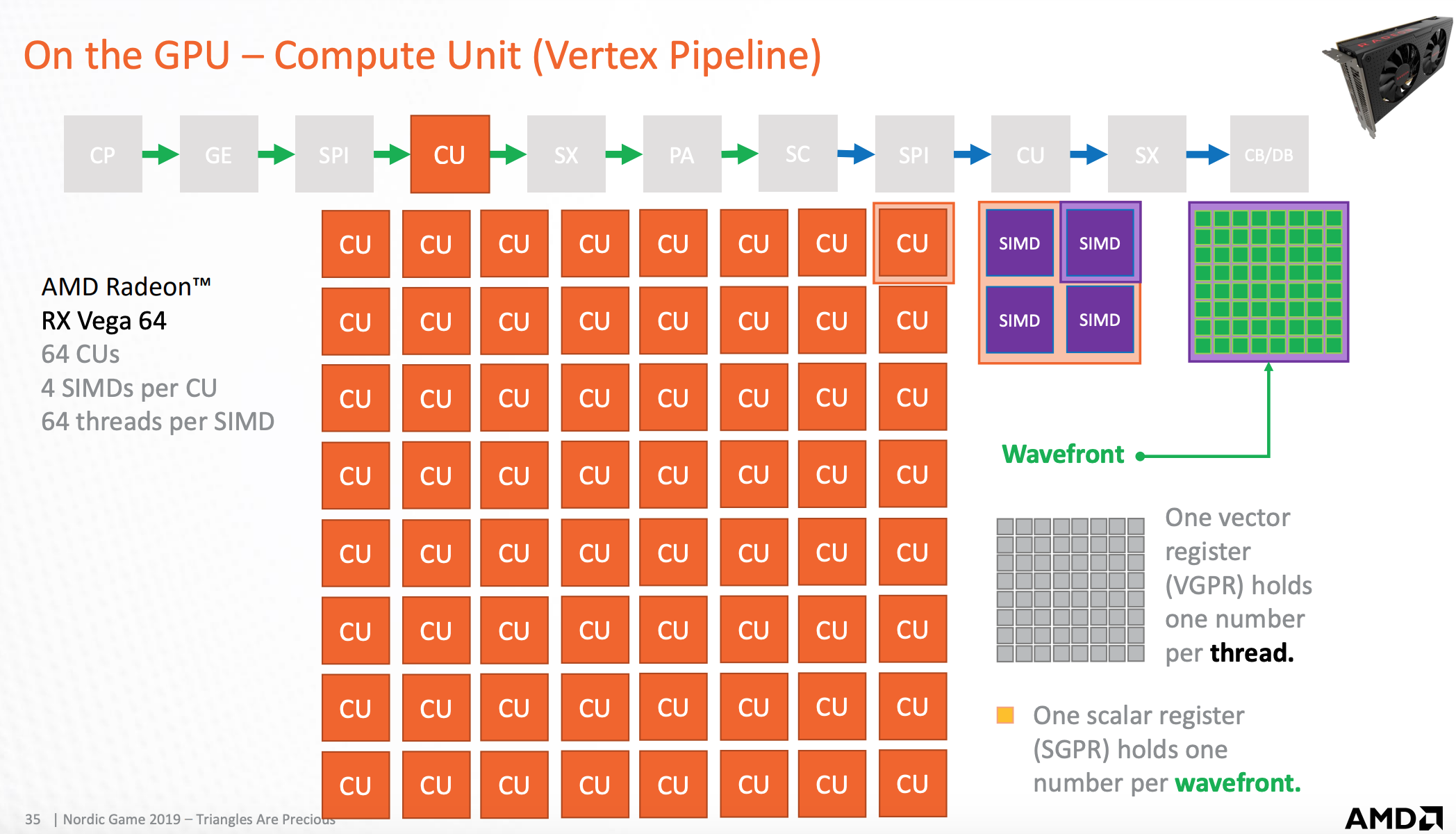
- 每个CU包含四个SIMD运算单元
- SIMD包含64个运算单元(线程),这64个运算单元称作Wavefront
- 每个Wavefront对应的Vector寄存器包含64个浮点存储位
- 每个Wavefront对应的Scalar寄存器包含一个浮点存储位
以下对应执行顶点shader的一个例子:
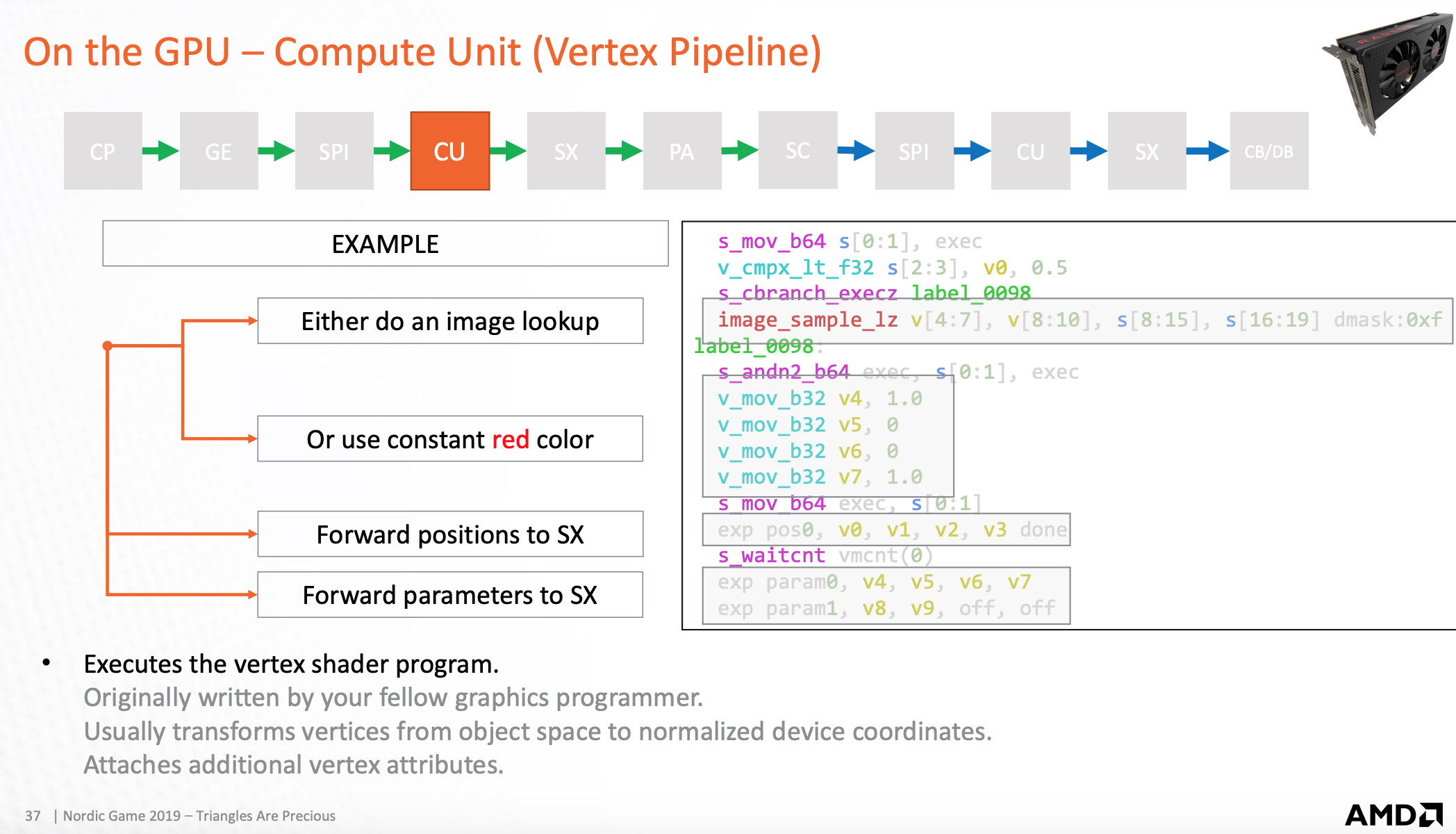
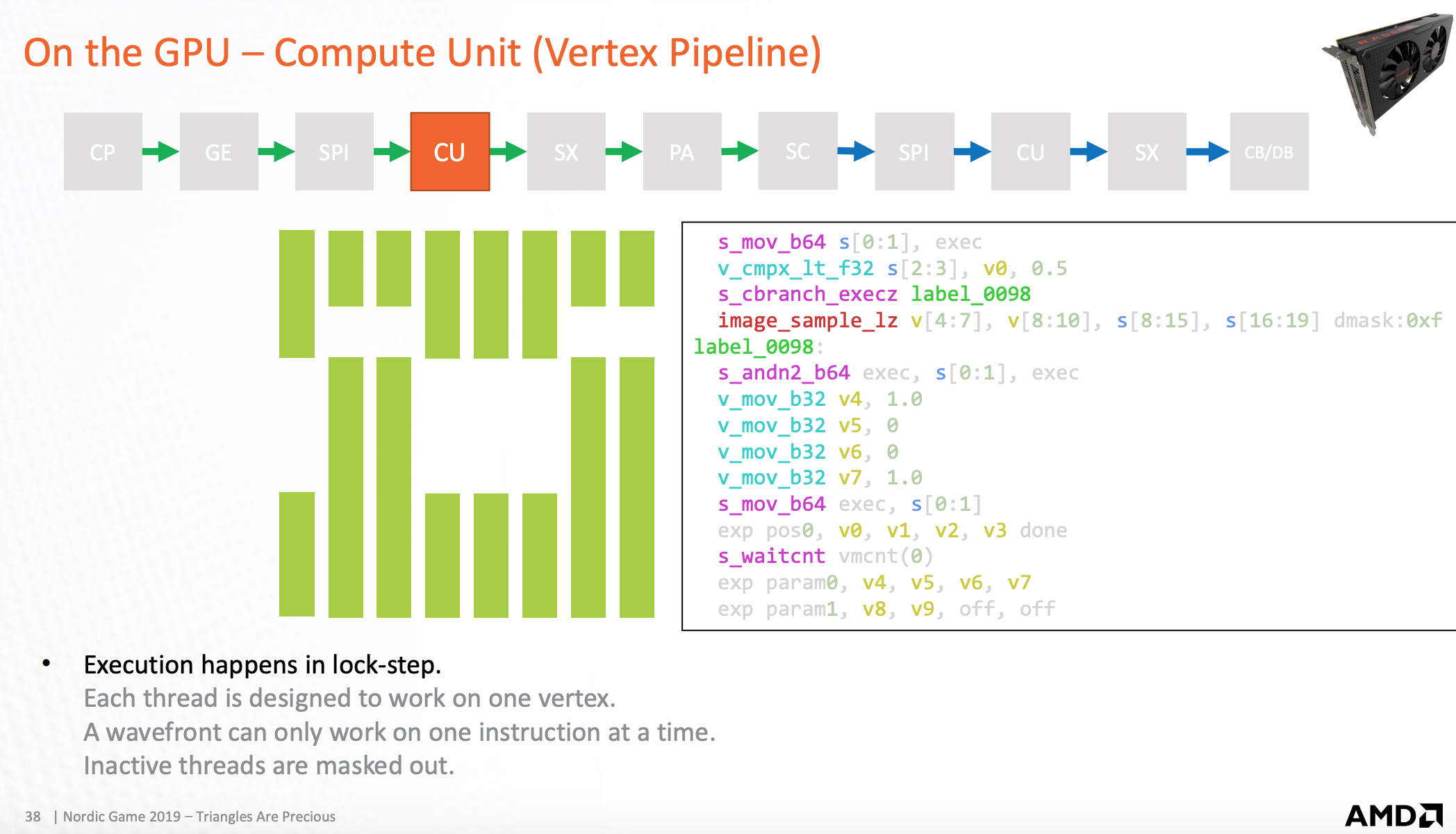
因为每个Wavefront执行的指令都一样,遇到分支的时候,检测对应线程上执行的数据如果无效,将舍弃
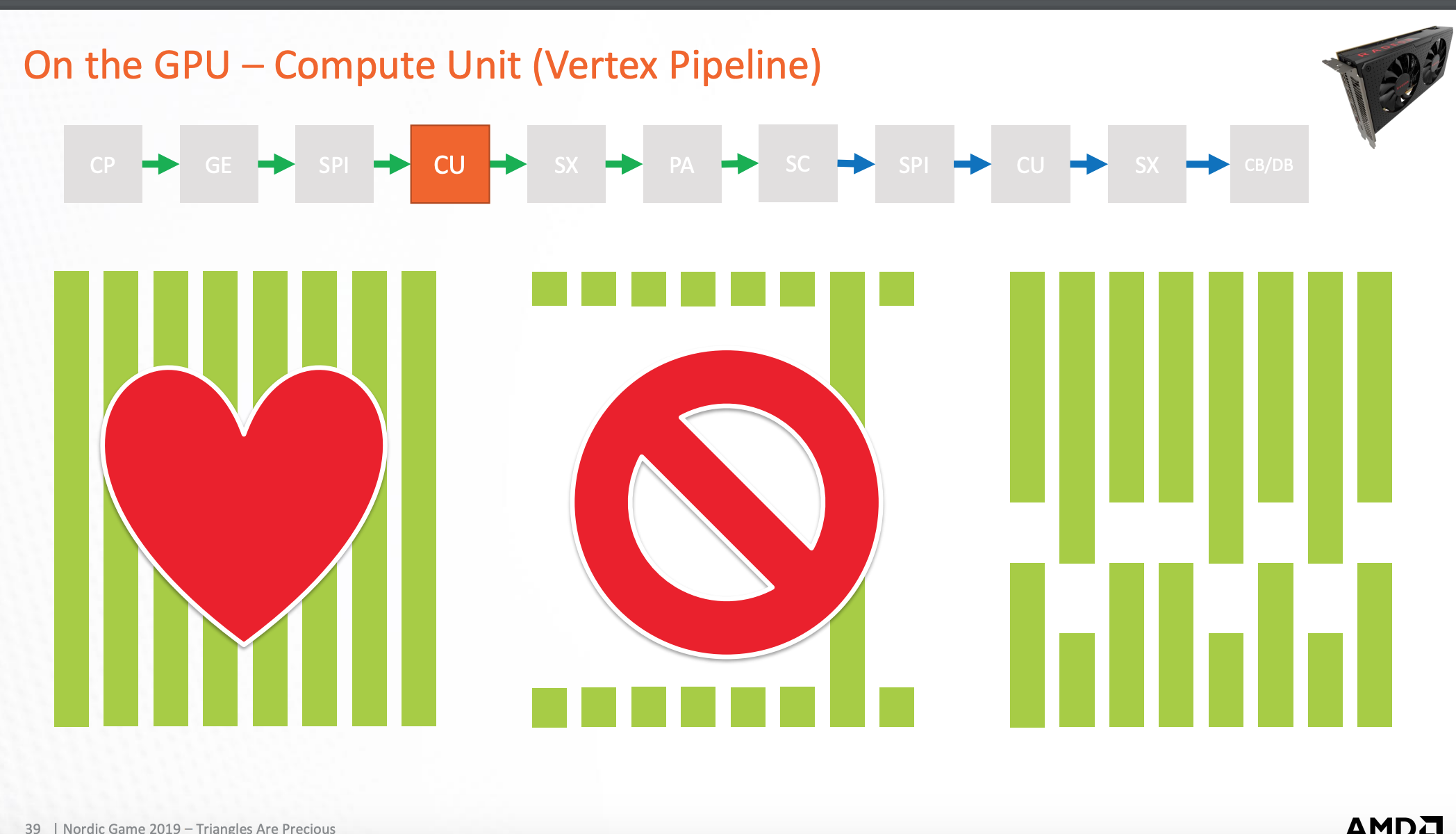
下面这张图展示了:最优结果,最坏结果,以及实践平均结果
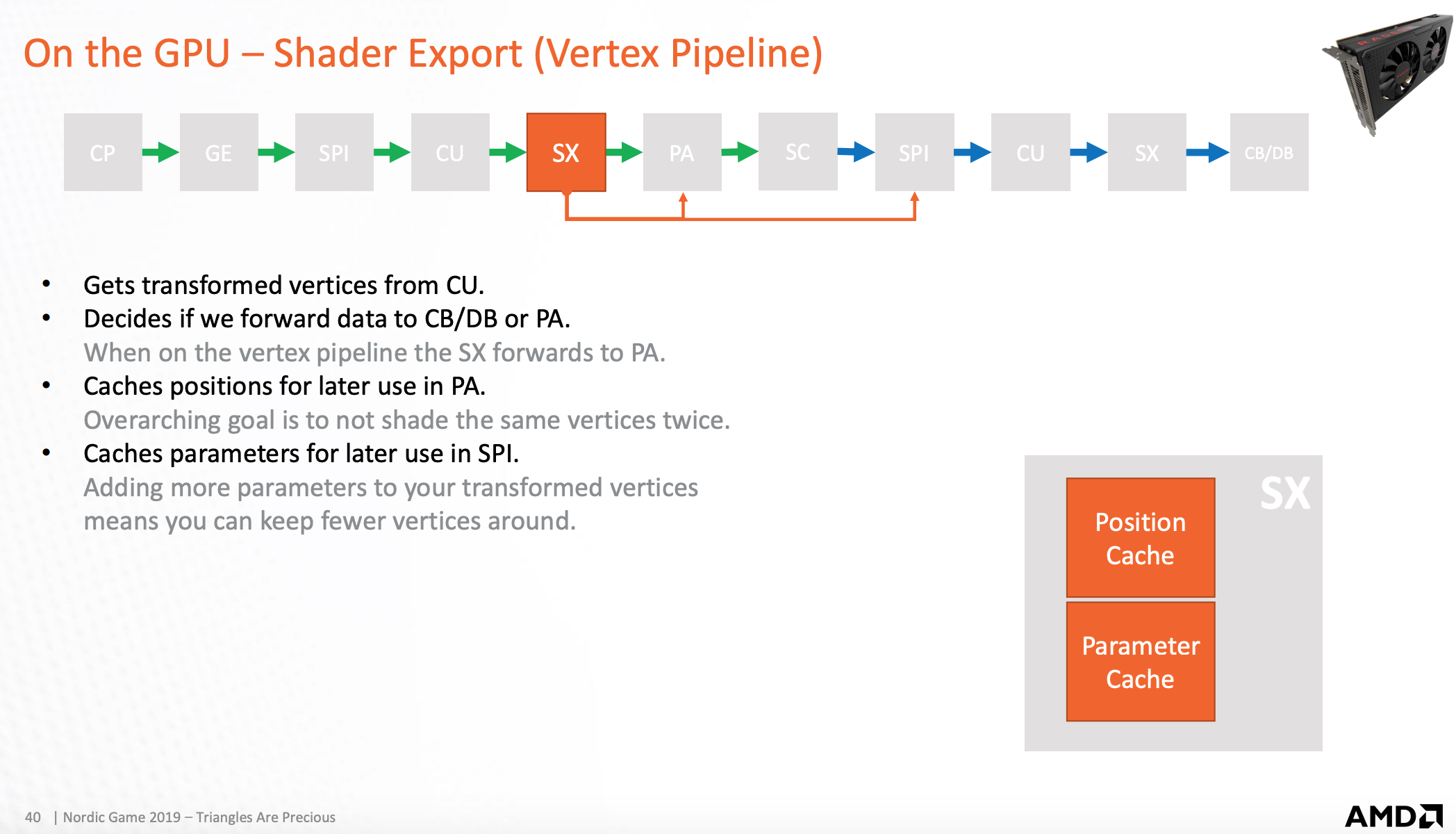
shader导出处理器(顶点管线)
基础汇编器
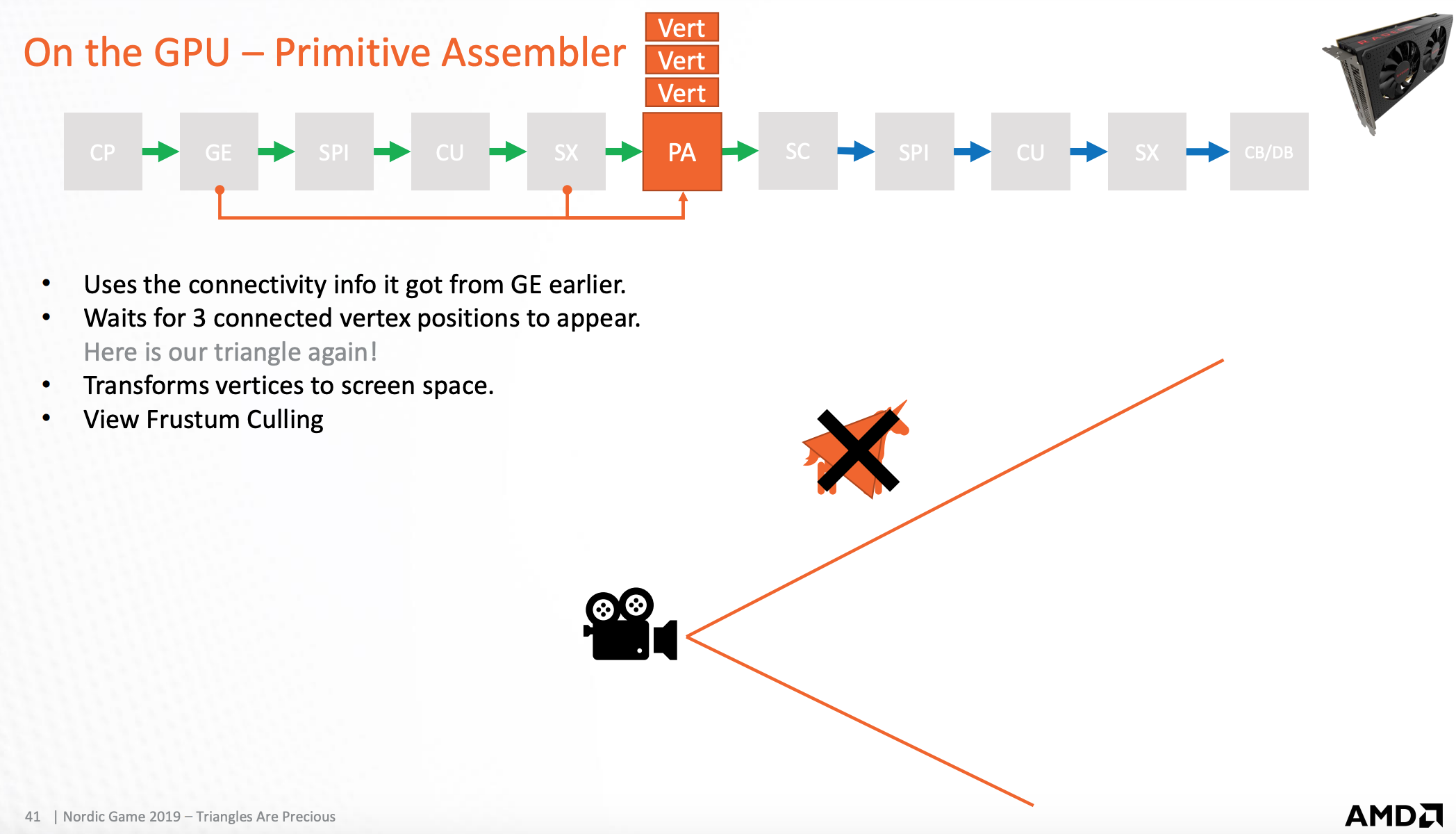
使用一系列优化方法,将不需要渲染的三角形舍弃
光栅化处理器
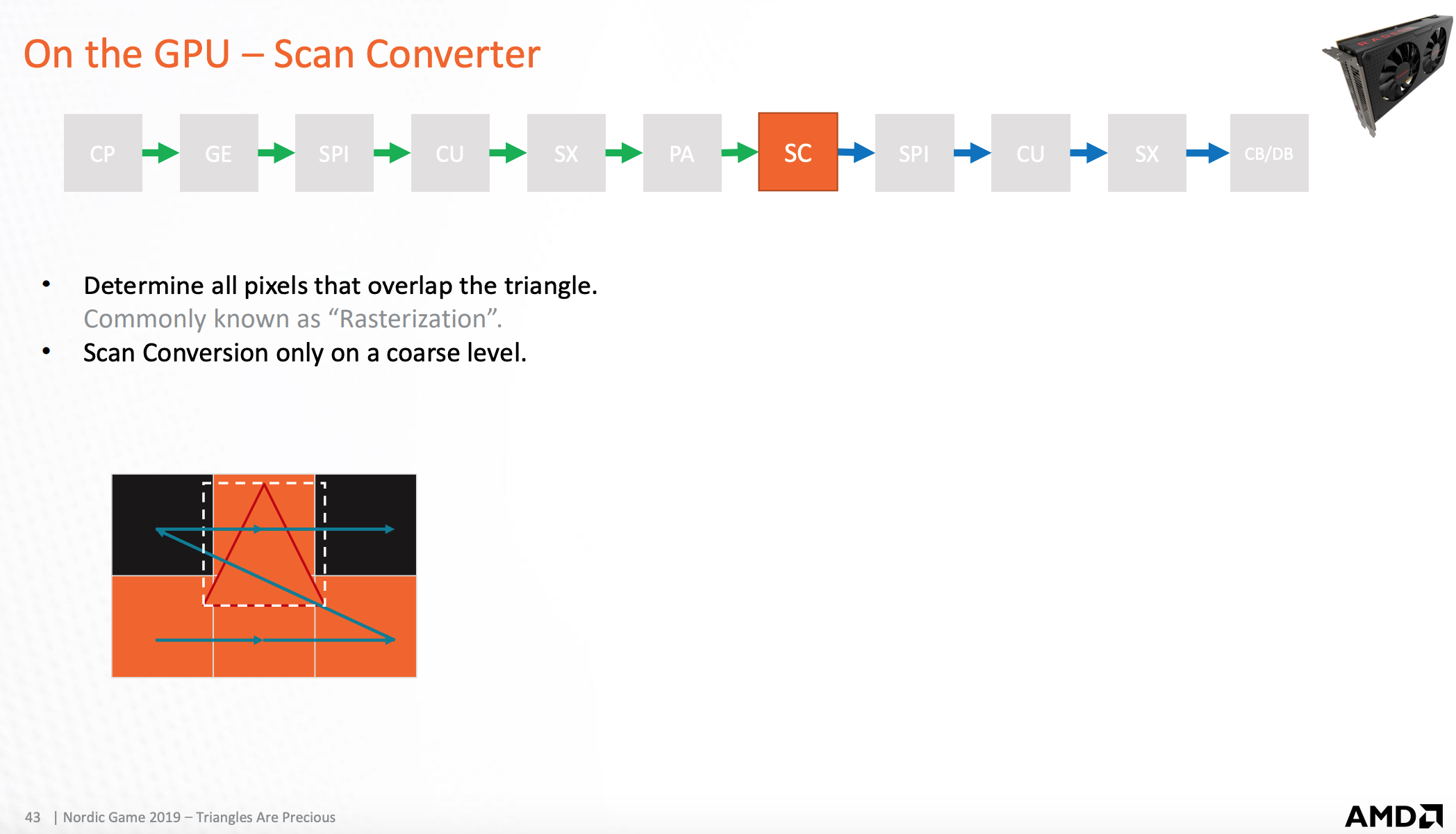
三角形形状和像素点分布的叠加图,这只是理论上用来说明光栅化原理
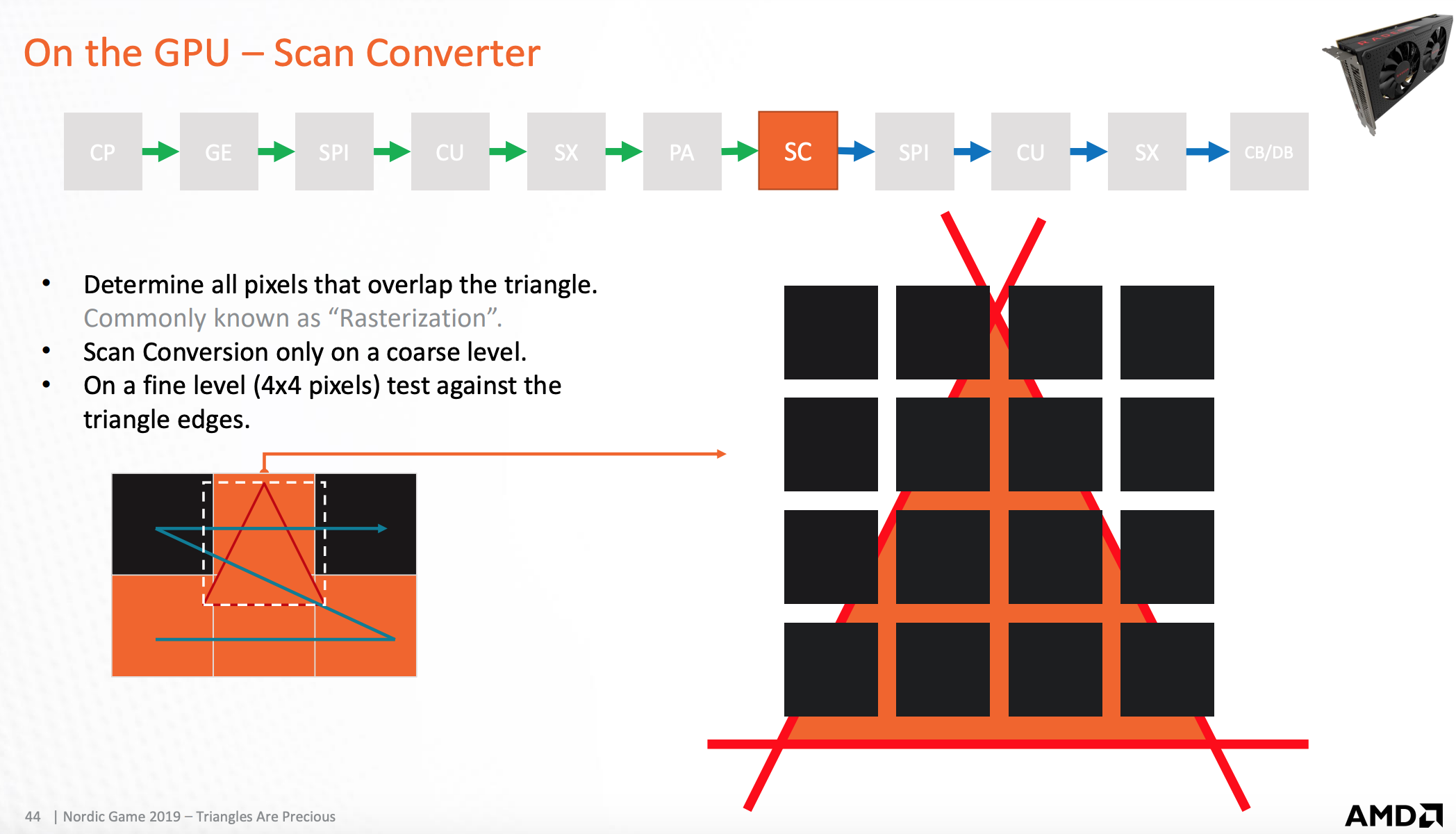
真实光栅化后,用来合成三角形的像素和三角形形状叠加图,用来理论上说明光栅化的原理
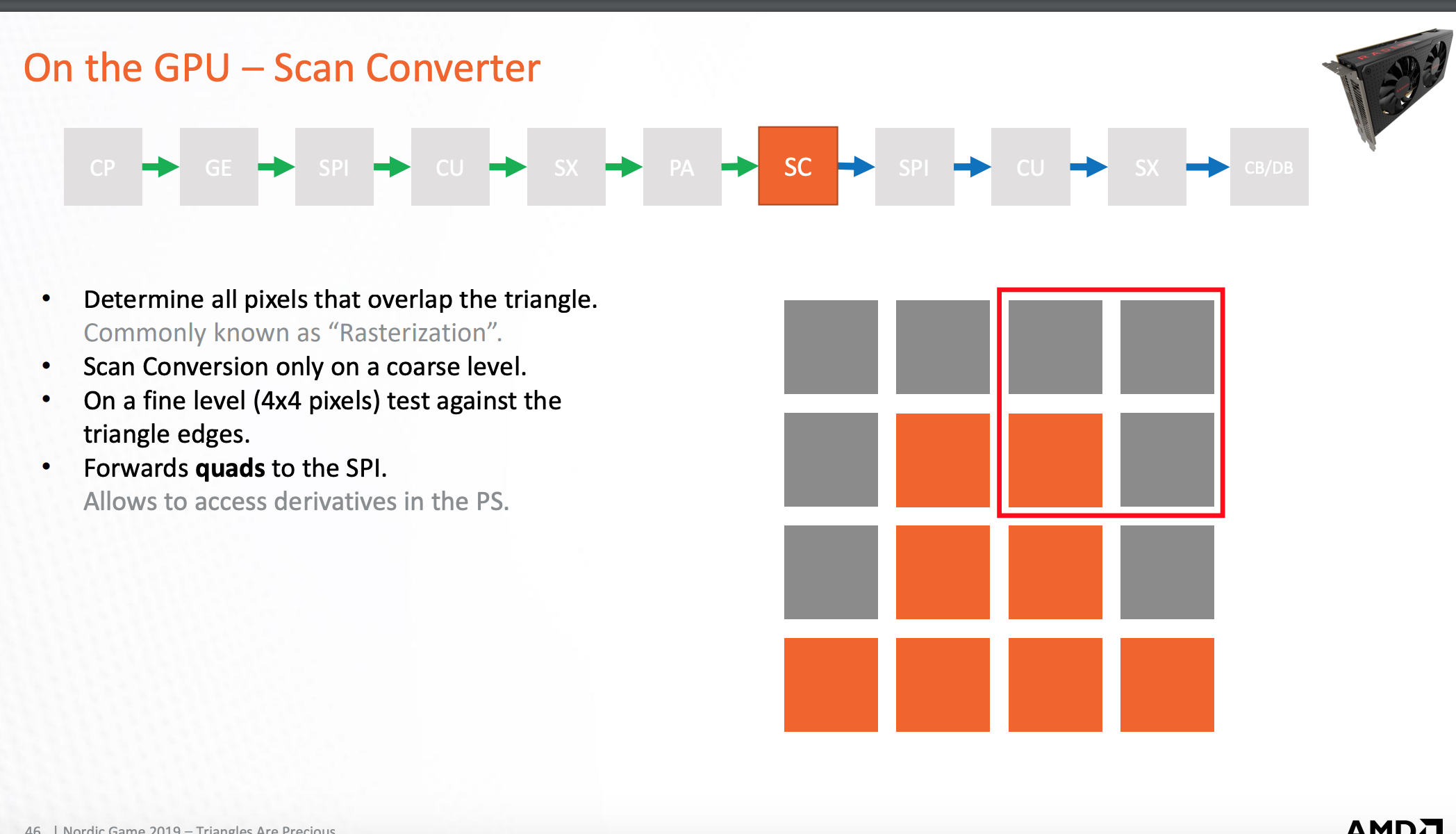
四个像素点为一组,用来像素点的shader处理
光栅化阶段的优化方式
shader 输入处理器(图元阶段)
运算单元(图元阶段)
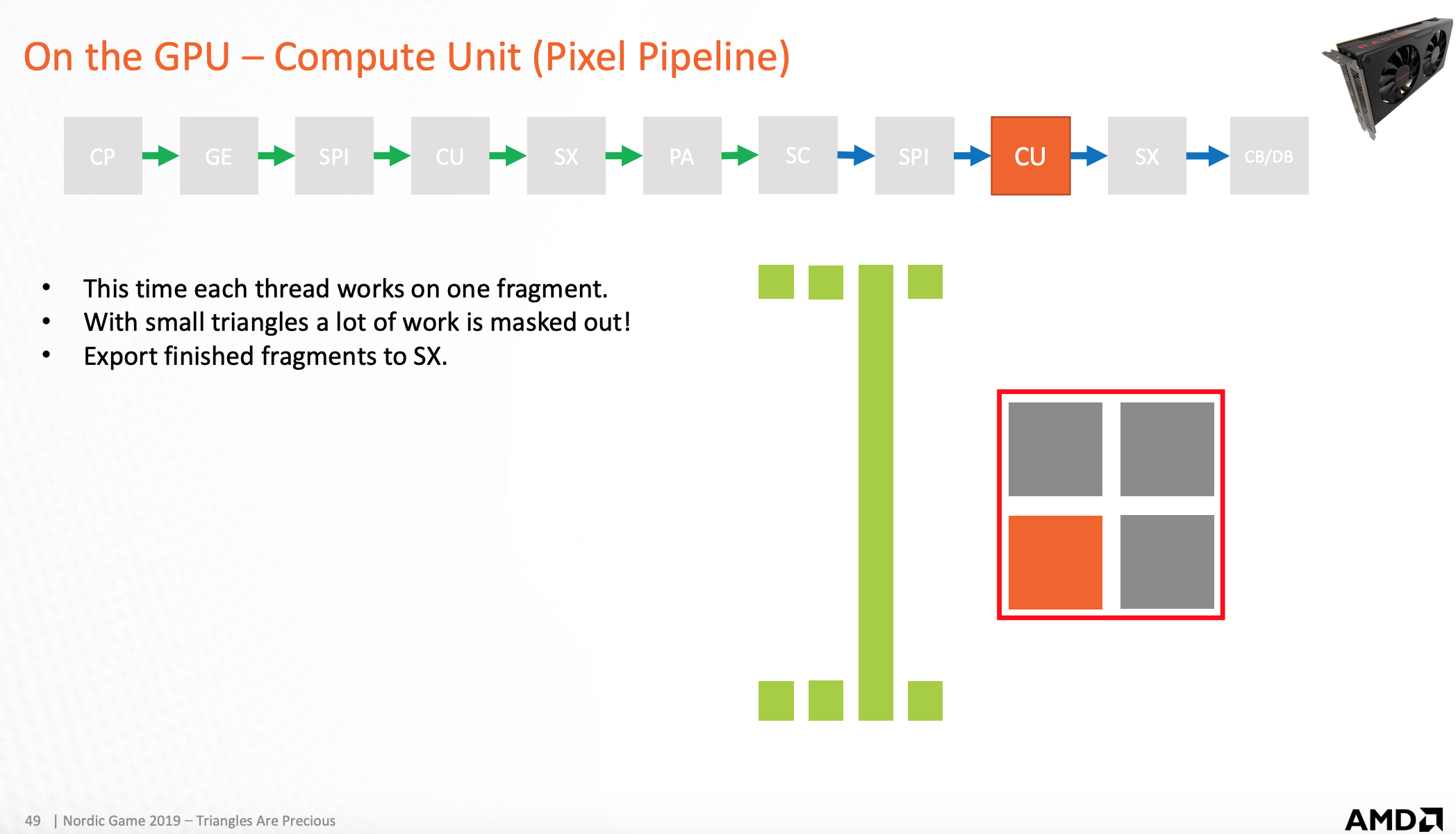
shader 输出处理器(图元阶段)

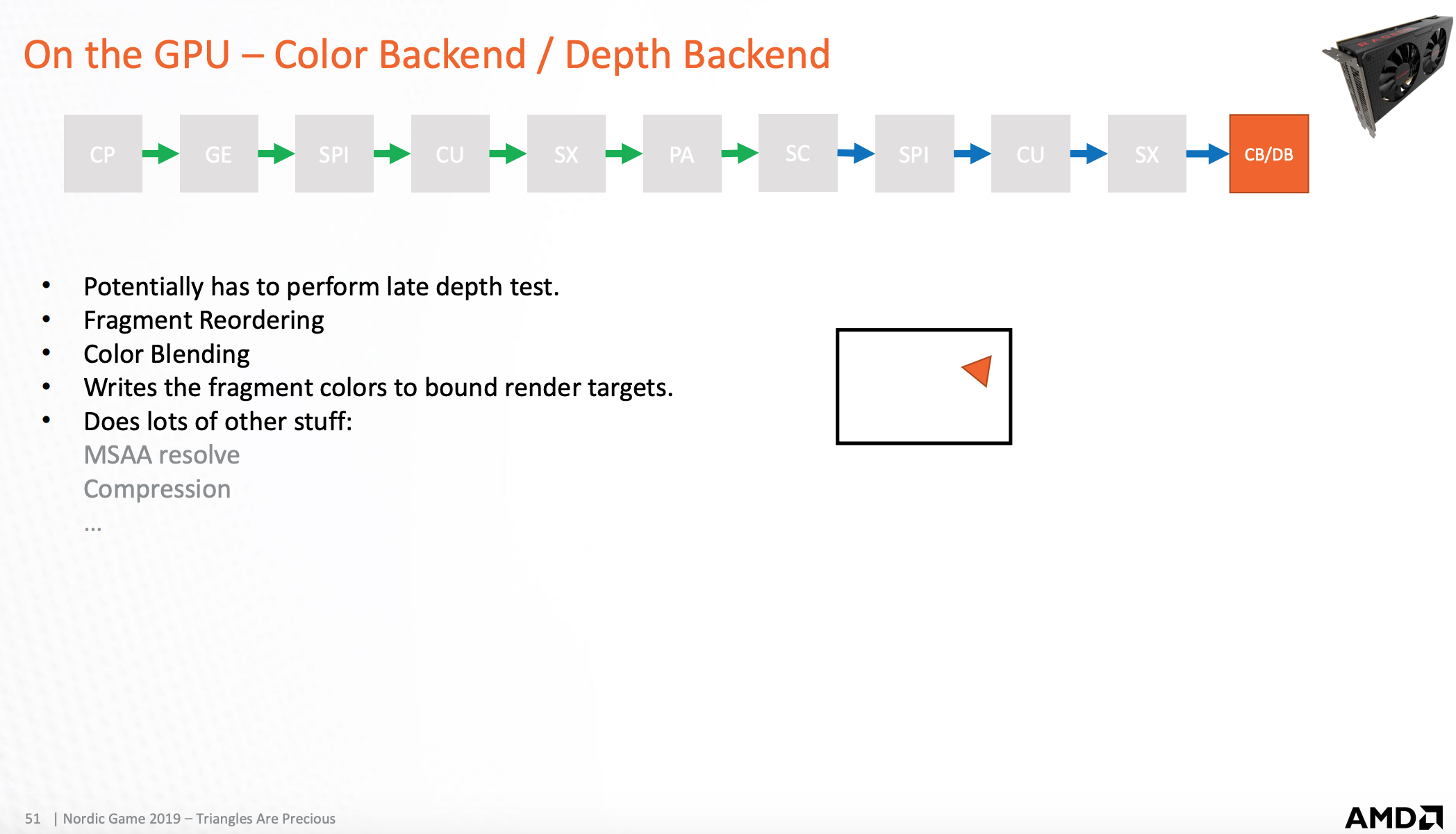
颜色/深度处理器
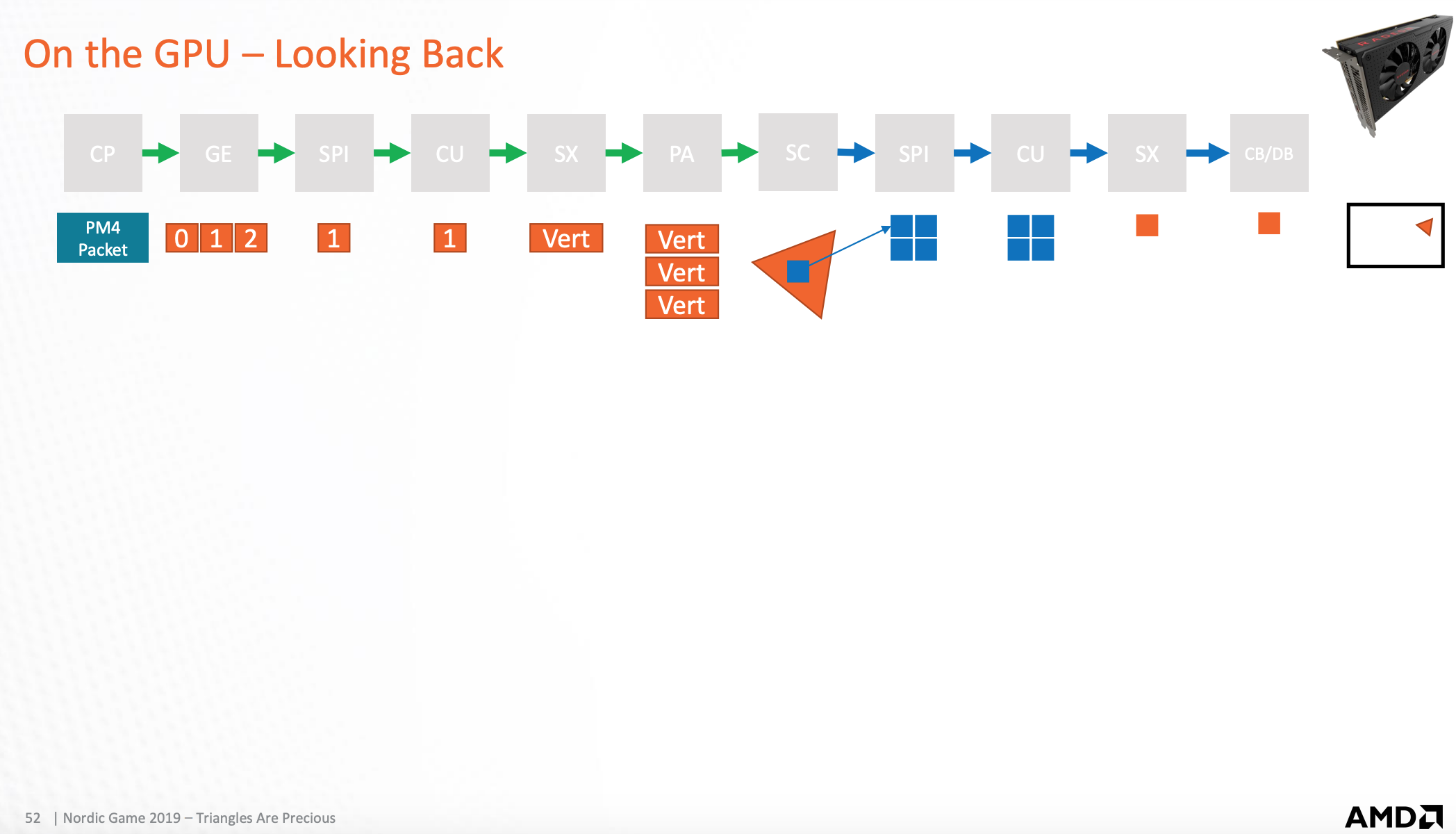
整个过程
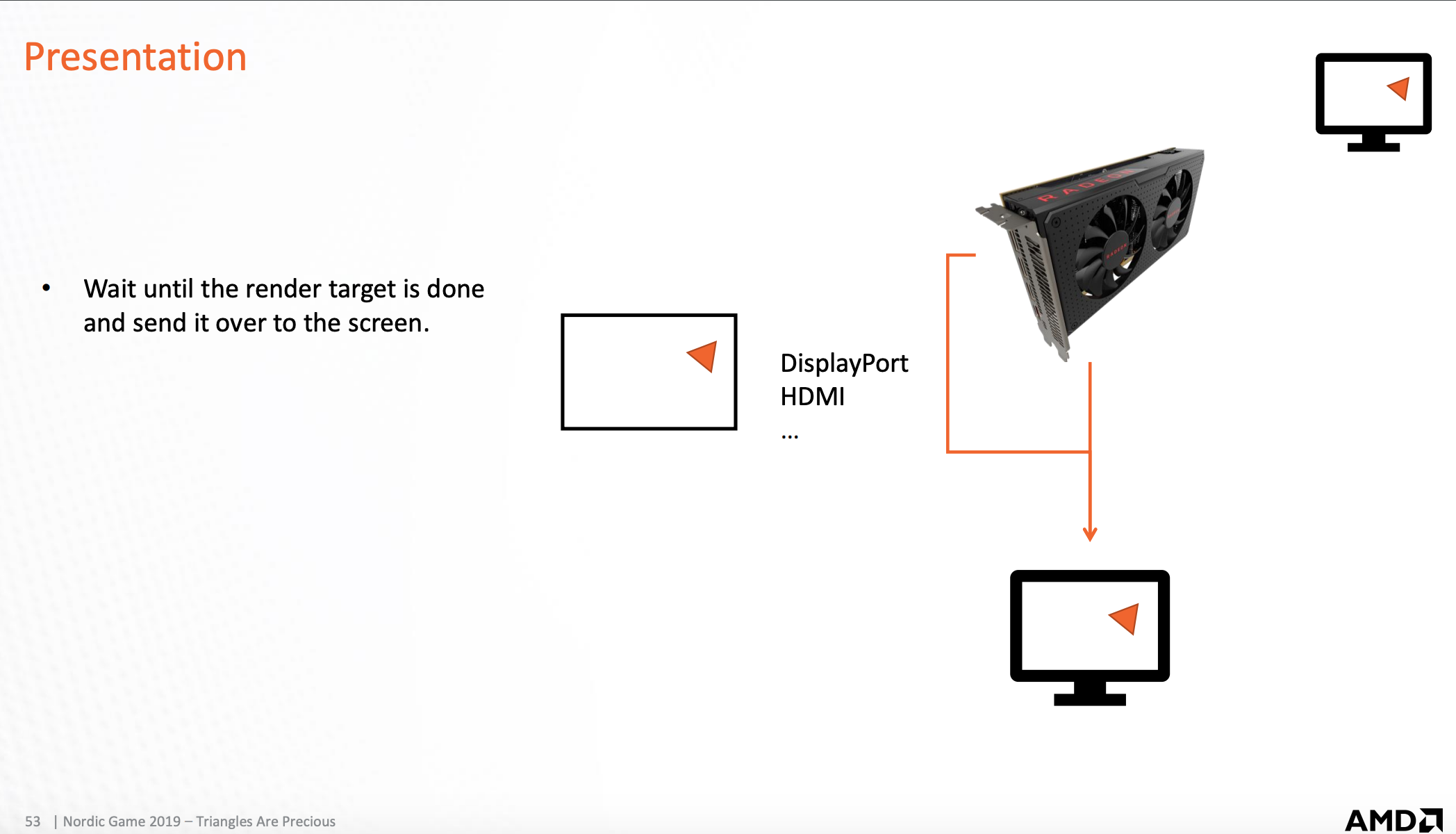
显示到屏幕
参考
A trip through the Graphics Pipeline 2011 – Fabian Giesen
Vega Instruction Set Architecture
The AMD GCN Architecture – Layla Mah
Radeon Southern Islands Acceleration (PM4)
Optimizing the Graphics Pipeline with Compute – Graham Wihlidal