介绍
SIMD(Single instruction, multiple Data),是并行运算的一个种类。硬件支持使用单条指令,同时处理多个数据的运算操作。
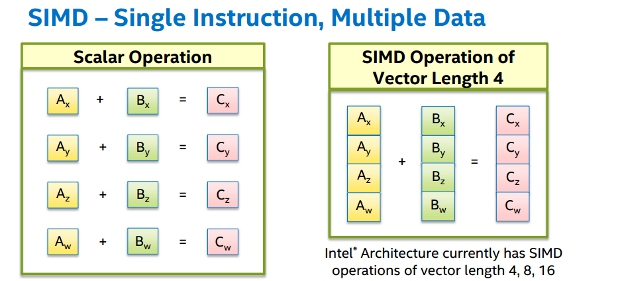
上图中使用单条指令需要执行四次得到运算结果,SIMD只需要执行行一次即可得到结果。
1970年SIMD已经被发明了,但是只到1990年代图形显卡被发明出来SIMD才大放光彩。每个处理器厂商都有自己的一套SIMD指令集:
- Intel (MMX/SSE/AVX)
- AMD (3Now!)
- MIPS (MDMX)
- Arm (NEON)
很明显想写出跨平台的代码,必须根据每家的指令集实现一套对应的库。还好编译器为我们提供了C语言版本的内置函数来调用SIMD指令,从而免去调用每个平台的汇编指令。但是需要注意的是每个编译器的实现细节并不一致。
为啥要发明SIMD
主要有两个原因:
- 许多应用对并行处理有需求(压缩,视频处理,游戏)
- 当前的cpu架构下,芯片设计者很容易实现
向量指令集(Vector Instructions)
在使用simd之前,先来介绍Intel向量指令集引入关键节点:
- MMX(Multimedia extension) register width 64bit, Pentium MMX 奔腾MMX (1996)
- SSE(Streaming SIMD extension) register width 128bit Pentium 3 奔腾3 (1999)
- AVX(Advanced vector extension) register width 256bit Sandy Bridge 酷睿四代 (2009)
- AVX-512 register width 512bit Skylake 酷睿六代 (2015)
以下是指令集对应处理器详细表格:
| Intel X86 | 处理器 | 寄存器长度 | 浮点支持 | 整数支持 | 时间 |
|---|---|---|---|---|---|
| X86-16 | 8086 | 1978 | |||
| 286 | 1982 | ||||
| X86-32 | 386 | 1985 | |||
| 486 | 1989 | ||||
| Pentium | 1993 | ||||
| MMX | Pentium MMX | 64bit | 8/16/32/64 bit | 1996 | |
| SSE | Pentium III | 128bit | 4x float | 8/16/32/64/128bit | 1999 |
| SSE2 | Pentium 4 | 128bit | 4xfloat/2xdouble | 8/16/32/64/128bit | 2000 |
| SSE3 | Pentium 4E | 128bit | 4xfloat/2xdouble | 8/16/32/64/128bit | 2004 |
| X86-64 | Pentium 4F | 128bit | 4xfloat/2xdouble | 8/16/32/64/128bit | 2004 |
| SSSE3 | Core 2 Duo | 128bit | 4xfloat/2xdouble | 8/16/32/64/128bit | 2006 |
| SSE4.1 | Penryn | 128bit | 4xfloat/2xdouble | 8/16/32/64/128bit | 2007 |
| SSE4.2 | Core i7(Nehalem) | 128bit | 4xfloat/2xdouble | 8/16/32/64/128bit | 2008 |
| AVX | Sandy Bridge | 256bit | 8xfloat/4xdouble | 8/16/32/64/128/256bit | 2009 |
| AVX2 | Haswell | 256bit | 8xfloat/4xdouble | 8/16/32/64/128/256bit | 2013 |
| FMA3 | 256bit | 8xfloat/4xdouble | 8/16/32/64/128/256bit | ||
| AVX-512 | Skylake-X | 512bit | 16xfloat/8xdouble | 8/16/32/64/128/256/512bit | 2015 |
ARM-V8 2011 年发布,2014年的iphone6首次使用,支持128bit的simd。
AMD Bulldozer 2011,直接引入了SSE4.1,SSE4.2,AVX
寄存器介绍
SSE3/SSE4/AVX128/XMM 寄存器总供有16个,xmm0—xmm15,每个长度如下:
// 2 doubles = 4 float
// 8/16/32/64/128 bit integers
128bit
|----------------| [xmm0]
...
|----------------| [xmm15]
AVX256 寄存器,总共有16个,ymm0-ymm15
// 4 doubles = 8 float
// 8/16/32/64/128/256 bit integers
256bit
|--------------------------------| [ymm0]
...
|--------------------------------| [ymm15]
AVX512寄存器,总共有32个,zmm0-zmm31
// 16 doubles = 32 float
// 8/16/32/64/128/256/512 bit integers
512bit
|----------------------------------------------------------------| [zmm0]
...
|----------------------------------------------------------------| [zmm31]
它们之间的关系:
// 32 zmm (avx512)
// 16 ymm (avx)
// 16 xmm (sse)
|32bit| [scalar]
|------128bit----| [xmm0]
|------------256bit--------------| [ymm0]
|-------------------------------512bit---------------------------| [zmm0]
...
|32bit| [scalar]
|------128bit----| [xmm15]
|------------256bit--------------| [ymm15]
|-------------------------------512bit---------------------------| [zmm15]
...
|32bit| [scalar]
|-------------------------------512bit---------------------------| [zmm31]
*/
xmm通过划分运算路径(path)数量,对应不同的数据类型长度:
// 多路(vector)整数
128bit
|---------------------------------------------------------------|
16路,每路为1byte
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8路,每路为2byte
|-------|-------|-------|-------|-------|-------|-------|-------|
4路,每路为4byte
|---------------|---------------|---------------|---------------|
2路,每路为8byte
|-------------------------------|-------------------------------|
// 多路浮点
4路单精度浮点,每路为4byte
|---------------|---------------|---------------|---------------|
2路双精度浮点,每路为8byte(sse2)
|-------------------------------|-------------------------------|
// 单路浮点
单精度浮点,4byte
| | | |---------------|
双精度浮点,8byte(sse2)
| |-------------------------------|
汇编指令简介
首先看两个4路单精度浮点相加,指令为:
addps %xmm0, %xmm1
// 需要注意的是这是AT&T风格的汇编指令
// AT&T 和 Intel汇编指令的区别为
// AT&T 可以看做是 source op target -> target
// Intel 可以看做是 target = target op src
|---------------|---------------|---------------|---------------| xmm0
+=
|---------------|---------------|---------------|---------------| xmm1
X86-64,所有的浮点运算都通过FPU的xmm运算,指令为:
addss %xmm0, %xmm1
| | | |---------------| xmm0
+=
| | | |---------------| xmm1
AVX指令集扩展了4路,三个操作符的双精度运算,说这个例子是因为shader里很多运算指令都是这种风格的
vaddpd %ymm0, %ymm1, %ymm2
|---------------|---------------|---------------|---------------| ymm0
+
|---------------|---------------|---------------|---------------| ymm1
=
|---------------|---------------|---------------|---------------| ymm2
指令名字
多路指令
addps说明:
p -> packed(vector) s -> single precision
vaddpd说明:
v -> 3 op p -> packed(vector) d -> double precision
单路指令
addss说明:
首个s -> single slot(scalar) 第二个s -> single precision
addsd说明:
s -> single slot d -> double precision
简单程序
求和函数:
float sum(const float* a, size_t n)
{
float ret = 0.0f;
for(size_t i = 0; i < n; ++i)
{
ret += a[i];
}
return ret;
}
编译为x86-64汇编后:
# clang x86-64 11.0.1
# rdi, rsi 分别为前两个参数a和n
sum(float const*, unsigned long):
xorps xmm0, xmm0 # result = 0
test rsi, rsi # n == 0
je .LBB1_3 # return result
xor eax, eax # i = 0
.LBB1_2:
addss xmm0, dword ptr [rdi + 4*rax] # result += a[i]
add rax, 1 # i++
cmp rsi, rax # i != n
jne .LBB1_2 # go to for loop
.LBB1_3:
ret
我们的目标就是将单路运算变为多路运算,减少指令执行次数,提高性能:
单路:
| | | |---------------| xmm0
+=
| | | |---------------| xmm1
替换为多路:
|---------------|---------------|---------------|---------------| xmm0
+=
|---------------|---------------|---------------|---------------| xmm1
使用Intel的Intrinsic版本的求和:
// 这里注意数组是4byte * 4 = 16byte对齐的
float sum_simd(const float* a, size_t n)
{
__m128 sRet = _mm_set1_ps(0);
for(size_t i = 0; i < n; i+=4)
{
__m128 m = _mm_load_ps(&a[i]);
sRet = _mm_add_ps(sRet, m);
}
__m128 tmp = _mm_unpackhi_pd(sRet, sRet);
tmp = _mm_add_ps(tmp, sRet);
sRet = _mm_shuffle_ps(tmp, tmp, 0x85);
sRet = _mm_add_ps(tmp, sRet);
return *(float*)&sRet;
}
编译为汇编后
sum_simd(float const*, unsigned long): # @sum_simd(float const*, unsigned long)
xorps xmm0, xmm0
test rsi, rsi
je .LBB3_3
xor eax, eax
.LBB3_2:
addps xmm0, xmmword ptr [rdi + 4*rax]
add rax, 4
cmp rax, rsi
jb .LBB3_2
.LBB3_3:
movaps xmm1, xmm0
unpckhpd xmm1, xmm0 # xmm1 = xmm1[1],xmm0[1]
addps xmm1, xmm0
movaps xmm0, xmm1
shufps xmm0, xmm1, 229 # xmm0 = xmm0[1,1],xmm1[2,3]
addss xmm0, xmm1
ret
总结
本篇介绍了SIMD的是什么,以及SIMD指令被引入的时间点。然后介绍了SIMD汇编指令,以及寄存器,最后通过求和函数的汇编代码熟悉了使用SIMD指令和使用X86指令的区别。下一篇介绍如何使用SIMD。