前言
上篇文章SIMD Intel Intrinsic介绍介绍了Intel Intrinsic的数据类型,以及相应的函数,本篇文章通过几个实用例子一方面是加深SIMD的理解,另一方面探讨如何组织工程和数据结构来更高效合理的利用SIMD提高程序性能。
点积(dot product)
向量$a=[a_1,a_2,…,a_n]$和向量$b=[b_1,b_2,…b_n]$的点积定义如下:
\[a.b=\sum_{i=1}^n a_ib_i=a_1b_1 + a_2b_2 + ... +a_nb_n\]对于Vec4的点积,程序实现如下:
struct Vec4
{
float x;
float y;
float z;
float w;
};
float dot(const Vec4& v1, const Vec4& v2)
{
return v1.x * v2.x + v1.y * v2.y + v1.z * v2.z + v1.w * v2.w;
}
因为Vec4由4个float组成,大小为128bit,使用SIMD最合适不过了。实现如下:
float simd_dot(const Vec4& v1, const Vec4& v2)
{
__m128 m1 = _mm_load_ps(&v1.x);
__m128 m2 = _mm_load_ps(&v2.x);
__m128 m = _mm_mul_ps(m1, m2); // x1*x2, y1*y2, z1*z2, w1*w2
__m128 tmp = _mm_shuffle_ps(m, m, _MM_SHUFFLE(0, 0, 3, 2)); // z1*z2, w1*w2, z1*z2, w1*w2
tmp = _mm_add_ps(m, tmp); // x1*x2 + z1*z2, y1*yz + w1*w2, -, -
__m128 ret = _mm_shuffle_ps(tmp, tmp, _MM_SHUFFLE(0, 0, 0, 1));
ret = _mm_add_ps(tmp, ret);
return *(float*)&ret;
}
这里看一下dot和simd_dot函数汇编,使用clang 12.0.0 -O2,结果如下:
dot(Vec4 const&, Vec4 const&): # @dot(Vec4 const&, Vec4 const&)
movss xmm0, dword ptr [rdi] # xmm0 = mem[0],zero,zero,zero
movss xmm1, dword ptr [rdi + 4] # xmm1 = mem[0],zero,zero,zero
mulss xmm0, dword ptr [rsi]
mulss xmm1, dword ptr [rsi + 4]
addss xmm1, xmm0
movsd xmm2, qword ptr [rdi + 8] # xmm2 = mem[0],zero
movsd xmm0, qword ptr [rsi + 8] # xmm0 = mem[0],zero
mulps xmm0, xmm2
addss xmm1, xmm0
shufps xmm0, xmm0, 85 # xmm0 = xmm0[1,1,1,1]
addss xmm0, xmm1
ret
simd_dot(Vec4 const&, Vec4 const&): # @simd_dot(Vec4 const&, Vec4 const&)
movaps xmm0, xmmword ptr [rdi]
mulps xmm0, xmmword ptr [rsi]
movaps xmm1, xmm0
unpckhpd xmm1, xmm0 # xmm1 = xmm1[1],xmm0[1]
addps xmm1, xmm0
movaps xmm0, xmm1
shufps xmm0, xmm1, 85 # xmm0 = xmm0[1,1],xmm1[1,1]
addss xmm0, xmm1
ret
如果有成百上千的Vec4需要求点积,这里就需要转换数据结构:
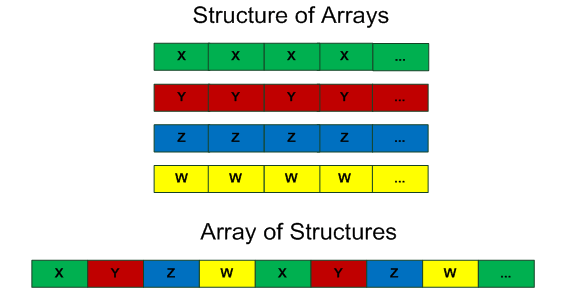
struct Vec4_AOS
{
float* x;
float* y;
float* z;
float* w;
}
void simd_fast_dot(const Vec4_AOS& v1, const Vec4_AOS& v2, Vec4* ret, size_t n)
{
for(size_t i = 0; i < n/4; ++i)
{
__m128 v1x = _mm_load_ps(v1.x + i * 4);
__m128 v2x = _mm_load_ps(v2.x + i * 4);
__m128 vx = _mm_mul_ps(v1x, v2x);
__m128 v1y = _mm_load_ps(v1.y + i * 4);
__m128 v2y = _mm_load_ps(v2.y + i * 4);
__m128 vxy = _mm_fmadd_ps(v1y, v2y, vx);
__m128 v1z = _mm_load_ps(v1.z + i * 4);
__m128 v2z = _mm_load_ps(v2.z + i *4);
__m128 vxyz = _mm_fmadd_ps(v1z, v2z, vxy);
__m128 v1w = _mm_load_ps(v1.w + i * 4);
__m128 v2w = _mm_load_ps(v2.w + i * 4);
__m128 vxyzw = _mm_fmadd_ps(v1w, v2w, vxyz);
_mm_store_ps(&ret->x, vxyzw);
++ret;
}
}
这里还以使用avx256进一步提高速度:
void simd_avx_dot(const Vec4_AOS& v1, const Vec4_AOS& v2, Vec4* ret, size_t n)
{
for(size_t i = 0; i < n/8; ++i)
{
__m256 v1x = _mm256_load_ps(v1.x + i * 8);
__m256 v2x = _mm256_load_ps(v2.x + i * 8);
__m256 vx = _mm256_mul_ps(v1x, v2x);
__m256 v1y = _mm256_load_ps(v1.y + i * 8);
__m256 v2y = _mm256_load_ps(v2.y + i * 8);
__m256 vxy = _mm256_fmadd_ps(v1y, v2y, vx);
__m256 v1z = _mm256_load_ps(v1.z + i * 8);
__m256 v2z = _mm256_load_ps(v2.z + i *8);
__m256 vxyz = _mm256_fmadd_ps(v1z, v2z, vxy);
__m256 v1w = _mm256_load_ps(v1.w + i * 8);
__m256 v2w = _mm256_load_ps(v2.w + i * 8);
__m256 vxyzw = _mm256_fmadd_ps(v1w, v2w, vxyz);
_mm256_store_ps(&ret->x, vxyzw);
ret += 2;
}
}
字符串
统计字符个数:
size_t count_chars_8(const char* data, size_t size, const char ch)
{
size_t total = 0;
while (size) {
if (*data == ch)
total += 1;
data += 1;
size -= 1;
}
return total;
}
使用SIMD:
size_t count_chars_128(const char* data, size_t size, const char ch)
{
size_t total = 0;
__m128i tocmp = _mm_set1_epi8(ch);
while (size) {
int mask = 0;
__m128i chunk = _mm_load_si128 ((__m128i const*)data);
__m128i results = _mm_cmpeq_epi8(chunk, tocmp);
mask = _mm_movemask_epi8(results);
total += _mm_popcnt_u32(mask);
data += 16;
size -= 16;
}
return total;
}